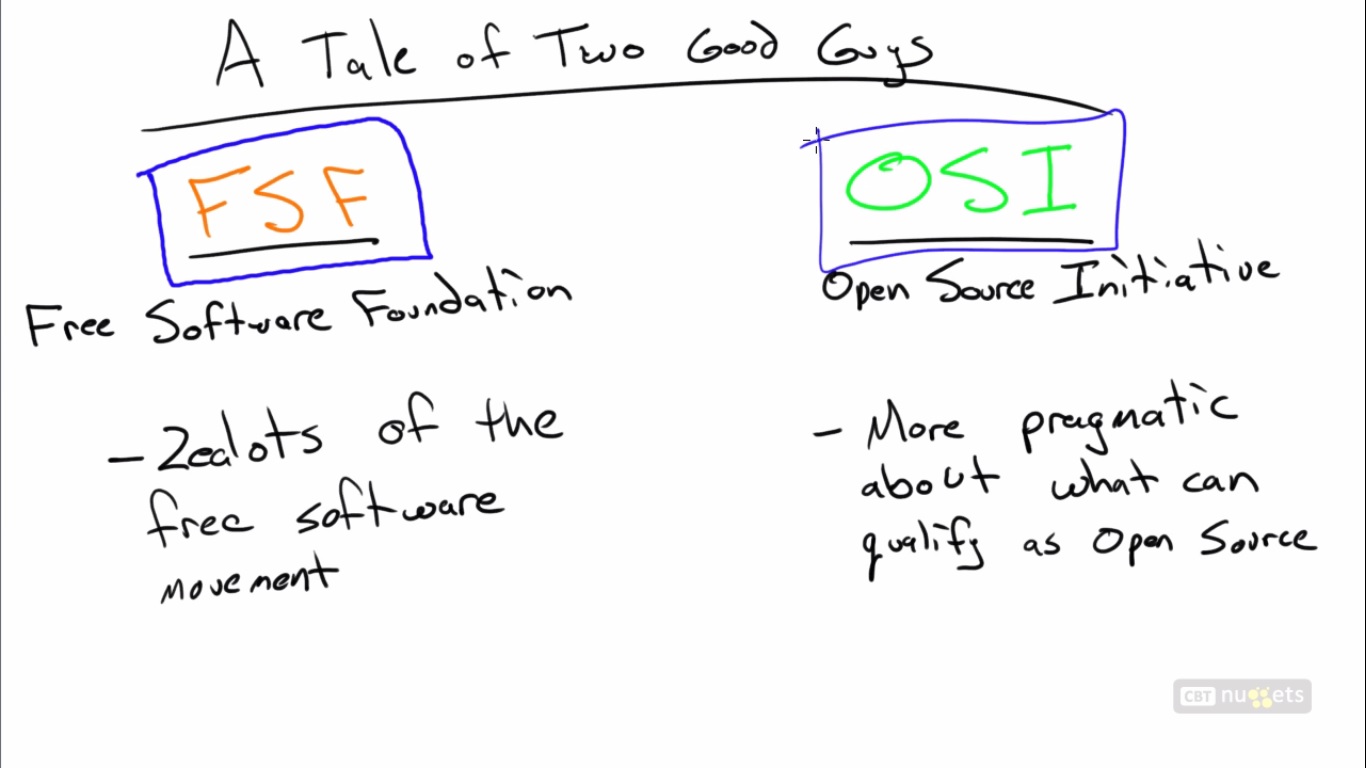
What’s the difference between the terms “Shell” and “Bash”?
A “shell” is any software that provides an interface to an operating system. For instance, explorer.exeis the default shell in Windows (though alternatives exist), and on OS X Finder provides much of the same functionality. On Linux/*nix, the shell could be part of the desktop environment (like Gnome orKDE), or can be a separate software component sitting on top of it (like Unity or Cinnamon).
The above examples are all graphical shells that use a combination of windows, menus, icons and other such elements to provide a graphical user interface (GUI) that can be interacted with using the mouse cursor. However, in the context of software like Bash, or writing scripts, “shell” is usually taken to mean a command-line interpreter, which performs largely the same duties as a graphical shell, except is entirely text-based.
Bash is a specific example of a command-line shell, and is probably one of the most well-known ones, being the default in many Linux distributions as well as OS X. It was designed as a replacement for the Bourne shell (Bash stands for “Bourne again shell”), one of the first Unix shells.
Examples of command-line shells on Windows include cmd.exe (aka Command Prompt) andPowerShell.
What is sh
sh (or the Shell Command Language) is a programming language described by the POSIX standard. It has many implementations (ksh88, dash, …). bash can also be considered an implementation of sh (see below).
Because sh is a specification, not an implementation, /bin/sh is a symlink (or a hard link) to an actual implementation on most POSIX systems.
What is bash
bash started as an sh-compatible implementation (although it predates the POSIX standard by a few years), but as time passed it has acquired many extensions. Many of these extensions may change the behavior of valid POSIX shell scripts, so by itself bash is not a valid POSIX shell. Rather, it is a dialect of the POSIX shell language.
bash supports a --posix switch, which makes it more POSIX-compliant. It also tries to mimic POSIX if invoked as sh.
sh == bash?
For a long time, /bin/sh used to point to /bin/bash on most GNU/Linux systems. As a result, it had almost become safe to ignore the difference between the two. But that started to change recently.
Some popular examples of systems where /bin/sh does not point to /bin/bash (and on some of which /bin/bash may not even exist) are:
- Modern Debian and Ubuntu systems, which symlink
shtodashby default; - Busybox, which is usually run during the Linux system boot time as part of
initramfs. It uses theashshell implementation. - BSDs. OpenBSD uses
pdksh, a descendant of the Korn shell. FreeBSD’sshis a descendant of the original UNIX Bourne shell.
Shebang line
Ultimately, it’s up to you to decide which one to use, by writing the «shebang» line.
E.g.
#!/bin/shwill use sh (and whatever that happens to point to),
#!/bin/bashwill use /bin/bash if it’s available (and fail with an error message if it’s not). Of course, you can also specify another implementation, e.g.
#!/bin/dashWhich one to use
For my own scripts, I prefer sh for the following reasons:
- it is standardized
- it is much simpler and easier to learn
- it is portable across POSIX systems — even if they happen not to have
bash, they are required to havesh
There are advantages to using bash as well. Its features make programming more convenient and similar to programming in other modern programming languages. These include things like scoped local variables and arrays. Plain sh is a very minimalistic programming language.
The Beginner’s Guide to Shell Scripting: The Basics

The term “shell scripting” gets mentioned often in Linux forums but many users aren’t familiar with it. Learning this easy and powerful programming method can help you save time, learn the command-line better, and banish tedious file management tasks.
What Is Shell Scripting?
Being a Linux user means you play around with the command-line. Like it or not, there are just some things that are done much more easily via this interface than by pointing and clicking. The more you use and learn the command-line, the more you see its potential. Well, the command-line itself is a program: the shell. Most Linux distros today use Bash, and this is what you’re really entering commands into.
Now, some of you who used Windows before using Linux may remember batch files. These were little text files that you could fill with commands to execute and Windows would run them in turn. It was a clever and neat way to get some things done, like run games in your high school computer lab when you couldn’t open system folders or create shortcuts. Batch files in Windows, while useful, are a cheap imitation of shell scripts.

Shell scripts allow us to program commands in chains and have the system execute them as a scripted event, just like batch files. They also allow for far more useful functions, such as command substitution. You can invoke a command, like date, and use it’s output as part of a file-naming scheme. You can automate backups and each copied file can have the current date appended to the end of its name. Scripts aren’t just invocations of commands, either. They’re programs in their own right. Scripting allows you to use programming functions – such as ‘for’ loops, if/then/else statements, and so forth – directly within your operating system’s interface. And, you don’t have to learn another language because you’re using what you already know: the command-line.
That’s really the power of scripting, I think. You get to program with commands you already know, while learning staples of most major programming languages. Need to do something repetitive and tedious? Script it! Need a shortcut for a really convoluted command? Script it! Want to build a really easy to use command-line interface for something? Script it!
Before You Begin
Before we begin our scripting series, let’s cover some basic information. We’ll be using the bash shell, which most Linux distributions use natively. Bash is available for Mac OS users and Cygwin on Windows, too. Since it’s so universal, you should be able to script regardless of your platform. In addition, so long as all of the commands that are referenced exist, scripts can work on multiple platforms with little to no tweaking required.
Scripting can easily make use of “administrator” or “superuser” privileges, so it’s best to test out scripts before you put them to work. Also use common sense, like making sure you have backups of the files you’re about to run a script on. It’s also really important to use the right options, like –i for the rm command, so that your interaction is required. This can prevent some nasty mistakes. As such, read through scripts you download and be careful with data you have, just in case things go wrong.
At their core, scripts are just plain text files. You can use any text editor to write them: gedit, emacs, vim, nano… This list goes on. Just be sure to save it as plain text, not as rich text, or a Word document. Since I love the ease of use that nano provides, I’ll be using that.
Script Permissions and Names
Scripts are executed like programs, and in order for this to happen they need to have the proper permissions. You can make scripts executable by running the following command on it:
chmod +x ~/somecrazyfolder/script1
This will allow anyone to run that particular script. If you want to restrict its use to just your user, you can use this instead:
chmod u+x ~/somecrazyfolder/script1
In order to run this script, you would have to cd into the proper directory and then run the script like this:
cd ~/somecrazyfolder
./script1
To make things more convenient, you can place scripts in a “bin” folder in your home directory:
~/bin
In many modern distros, this folder no longer is created by default, but you can create it. This is usually where executable files are stored that belong to your user and not to other users. By placing scripts here, you can just run them by typing their name, just like other commands, instead of having to cd around and use the ‘./’ prefix.
Before you name a script, though, you should the following command to check if you have a program installed that uses that name:
which [command]
A lot of people name their early scripts “test,” and when they try to run it in the command-line, nothing happens. This is because it conflicts with the test command, which does nothing without arguments. Always be sure your script names don’t conflict with commands, otherwise you may find yourself doing things you don’t intend to do!
Scripting Guidelines

As I mentioned before, every script file is essentially plain text. That doesn’t mean you can write what you want all willy-nilly, though. When a text file is attempted to be executed, shells will parse through them for clues as to whether they’re scripts or not, and how to handle everything properly. Because of this, there are a few guidelines you need to know.
- Every script should being with “#!/bin/bash”
- Every new line is a new command
- Comment lines start with a #
- Commands are surrounded by ()
The Hash-Bang Hack
When a shell parses through a text file, the most direct way to identify the file as a script is by making your first line:
#!/bin/bash
If you use another shell, substitute its path here. Comment lines start with hashes (#), but adding the bang (!) and the shell path after it is a sort of hack that will bypass this comment rule and will force the script to execute with the shell that this line points to.
New Line = New Command
Every new line should be considered a new command, or a component of a larger system. If/then/else statements, for example, will take over multiple lines, but each component of that system is in a new line. Don’t let a command bleed over into the next line, as this can truncate the previous command and give you an error on the next line. If your text editor is doing that, you should turn off text-wrapping to be on the safe side. You can turn off text wrapping in nano bit hitting ALT+L.
Comment Often with #s
If you start a line with a #, the line is ignored. This turns it into a comment line, where you can remind yourself of what the output of the previous command was, or what the next command will do. Again, turn off text wrapping, or break you comment into multiple lines that all begin with a hash. Using lots of comments is a good practice to keep, as it lets you and other people tweak your scripts more easily. The only exception is the aforementioned Hash-Bang hack, so don’t follow #s with !s. 😉
Commands Are Surrounded By Parentheses
In older days, command substitutions were done with single tick marks (`, shares the ~ key). We’re not going to be touching on this yet, but as most people go off and explore after learning the basics, it’s probably a good idea to mention that you should use parentheses instead. This is mainly because when you nest – put commands inside other commands – parentheses work better.
Your First Script
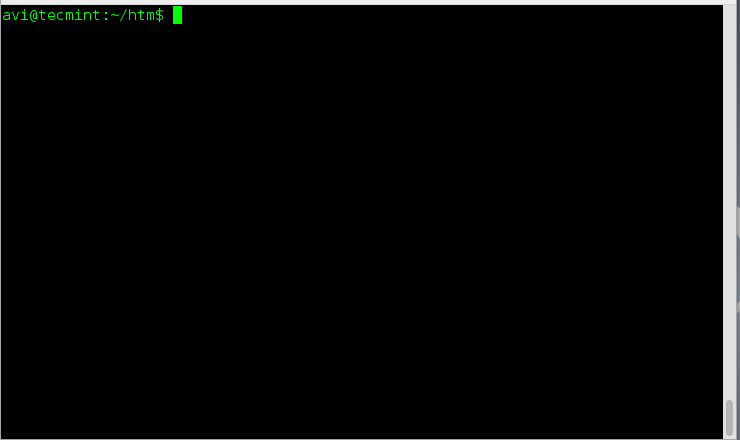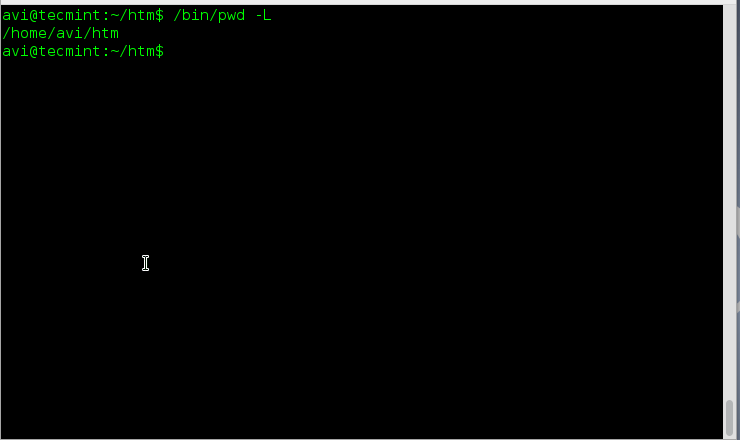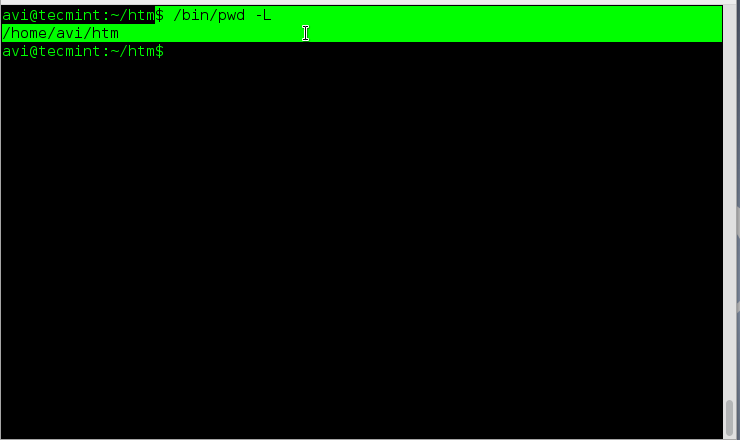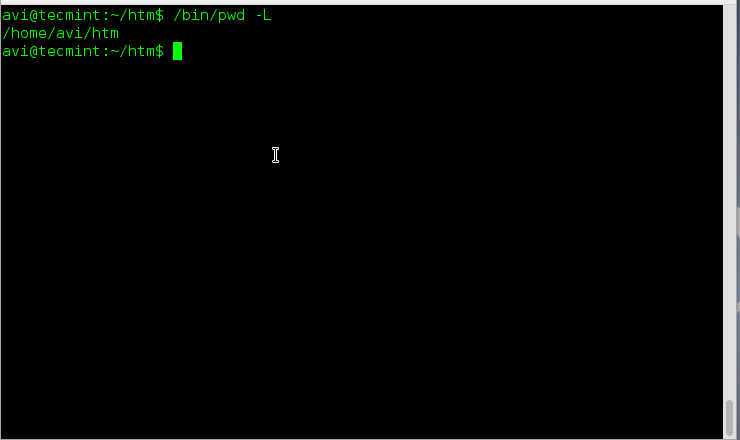
Let’s start with a simple script that allows you to copy files and append dates to the end of the filename. Let’s call it “datecp”. First, let’s check to see if that name conflicts with something:

You can see that there’s no output of the which command, so we’re all set to use this name.
Let’s create a blank file in the ~/bin folder:
touch ~/bin/datecp

And, let’s change the permission now, before we forget:

Let’s start building our script then. Open up that file in your text editor of choice. Like I said, I like the simplicity of nano.
nano ~/bin/datecp
And, let’s go ahead and put in the prerequisite first line, and a comment about what this script does.

Next, let’s declare a variable. If you’ve ever taken algebra, you probably know what a that is. A variable allows us to store information and do things with it. Variables can “expand” when referenced elsewhere. That is, instead of displaying their name, they will display their stored contents. You can later tell that same variable to store different information, and any instruction that occurs after that will use the new information. It’s a really fancy placeholder.
What will we put in out variable? Well, let’s store the date and time! To do this, we’ll call upon the date command.
Take a look at the screenshot below for how to build the output of the date command:

You can see that by adding different variables that start with %, you can change the output of the command to what you want. For more information, you can look at the manual page for the date command.
Let’s use that last iteration of the date command, “date +%m_%d_%y-%H.%M.%S”, and use that in our script.

If we were to save this script right now, we could run it and it would give us the output of the date command like we’d expect:

But, let’s do something different. Let’s give a variable name, like date_formatted to this command. The proper syntax for this is as follows:
variable=$(command –options arguments)
And for us, we’d build it like this:
date_formatted=$(date +%m_%d_%y-%H.%M.%S)

This is what we call command substitution. We’re essentially telling bash that whenever the variable “date_formatted” shows up, to run the command inside the parentheses. Then, whatever output the commands gives should be displayed instead of the name of the variable, “date_formatted”.
Here’s an example script and its output:


Note that there are two spaces in the output. The space within the quotes of the echo command and the space in front of the variable are both displayed. Don’t use spaces if you don’t want them to show up. Also note that without this added “echo” line, the script would give absolutely no output.
Let’s get back to our script. Let’s next add in the copying part of the command.
cp –iv $1 $2.$date_formatted

This will invoke the copy command, with the –i and –v options. The former will ask you for verification before overwriting a file, and the latter will display what is being down on the command-line.
Next, you can see I’ve added the “$1” option. When scripting, a dollar sign ($) followed by a number will denote that numbered argument of the script when it was invoked. For example, in the following command:
cp –iv Trogdor2.mp3 ringtone.mp3
The first argument is “Trogdor2.mp3” and the second argument is “ringtone.mp3”.
Looking back at our script, we can see that we’re referencing two arguments:

This means that when we run the script, we’ll need to provide two arguments for the script to run correctly. The first argument, $1, is the file that will be copied, and is substituted as the “cp –iv” command’s first argument.
The second argument, $2, will act as the output file for the same command. But, you can also see that it’s different. We’ve added a period and we’ve referenced the “date_formatted” variable from above. Curious as to what this does?
Here’s what happens when the script is run:

You can see that the output file is listed as whatever I entered for $2, followed by a period, then the output of the date command! Makes sense, right?
Now when I run the datecp command, it will run this script and allow me to copy any file to a new location, and automatically add the date and time to end of the filename. Useful for archiving stuff!
Shell scripting is at the heart of making your OS work for you. You don’t have to learn a new programming language to make it happen, either. Try scripting with some basic commands at home and start thinking of what you can use this for.
Bash Scripting Introduction Tutorial with 5 Practical Examples
Similar to our on-going Unix Sedand Unix Awk series, we will be posting several articles on Bash scripting, which will cover all the bash scripting techniques with practical examples.
Shell is a program, which interprets user commands. The commands are either directly entered by the user or read from a file called the shell script.
Shell is called as an interactive shell, when it reads the input from the user directly.
Shell is called as an non-interactive shell, when it reads commands from a file and executes it. In this case, shell reads each line of a script file from the top to the bottom, and execute each command as if it has been typed directly by the user.
Print the value of built in shell variable $-, to know whether the shell is an interactive or non-interactive.
# echo $- himBH
Note: $- variable contains an “i” when the shell is interactive.
Unix has variety of Shells. Bourne shell (sh), Bourne again shell (bash), C shell (csh), Korn shell (ksh), Tenex C shell (tcsh). Use the which or whereis unix commands to find out where a specific shell is located as shown below.
# which bash /bin/bash # whereis bash bash: /bin/bash /usr/share/man/man1/bash.1.gz
You can switch between the shells, by typing the shell name. For example, type csh to switch to C shell.
Writing and execution of shell script
Example 1. Hello World Bash Script
- Create a script by typing the following two lines into a file using your favourite editor.
$ cat helloworld.sh #!/bin/bash echo Hello World
- You can choose any name for the file. File name should not be same as any of the Unix built-in commands.
- Script always starts with the two character ‘#!’ which is called as she-bang. This is to indicate that the file is a script, and should be executed using the interpreter (/bin/bash) specified by the rest of the first line in the file.
- Execute the script as shown below. If you have any issues executing a shell script, refer to shell script execution tutorial
$ bash helloworld.sh Hello World
- When you execute the command “bash helloworld.sh”, it starts the non-interactive shell and passes the filename as an argument to it.
- The first line tells the operating system which shell to spawn to execute the script.
- In the above example, bash interpreter which interprets the script and executes the commands one by one from top to bottom.
- You can even execute the script, with out leading “bash” by:
- Change the permission on the script to allow you(User) to execute it, using the command “chmod u+x helloworld.sh”.
- Directory containing the script should be included in the PATH environment variable. If not included, you can execute the script by specifying the absolute path of the script.
- echo is a command which simply outputs the argument we give to it. It is also used to print the value of the variable.
Bash-Startup files
As we discussed earlier in our execution sequence for .bash_profile and related files article, when the bash is invoked as an interactive shell, it first reads and executes commands from /etc/profile. If /etc/profile doesn’t exist, it reads and executes the commands from ~/.bash_profile, ~/.bash_login and ~/.profile in the given order. The –noprofile option may be used when the shell is started to inhibit this behavior.
Typically your bash_profile executes ~/.bashrc. If you like, you can show a welcome message. This only runs when you first log in. You can export the variables whatever you want, and you can set the aliases which will be running and available once you opened the shell. When a login shell exits, Bash reads and executes commands from the file ~/.bash_logout.
Example 2. Print a welcome message when you login
Type the following contents in your bash_profile file. If the file doesn’t exist, create a file with the below content.
$ cat ~/.bash_profile hname=`hostname` echo "Welcome on $hname."
When you login to an interactive shell, you will see the welcome messages as shown below.
login as: root root@dev-db's password: Welcome on dev-db
Example 3. Print system related information
When you login to an interactive shell, you can show the name of the kernel installed in the server, bash version, uptime and time in the server.
$cat ~/.bash_profile hname=`hostname` echo "Welcome on $hname." echo -e "Kernel Details: " `uname -smr` echo -e "`bash --version`" echo -ne "Uptime: "; uptime echo -ne "Server time : "; date
When you launch an interactive shell, it prints the message as shown below.
login as: root root@dev-db's password: Welcome on dev-db Kernel Information: Linux 2.6.18-128 x86_64 GNU bash, version 3.2.25(1)-release (x86_64-redhat-linux-gnu) Copyright (C) 2005 Free Software Foundation, Inc. Uptime: 11:24:01 up 21 days, 13:15, 3 users, load average: 0.08, 0.18, 0.11 Server time : Tue Feb 22 11:24:01 CET 2010
Example 4. Print the last login details
If multiple users are using the same machine with same login, then details like the machine from which the last login happened, and time at which they logged in, would be the most useful details. This example prints the last login details during the starting of an interactive shell.
$ cat ~/.bash_profile hname=`hostname` echo "Welcome on $hname."
echo -e "Kernel Details: " `uname -smr` echo -e "`bash --version`" echo -ne "Uptime: "; uptime echo -ne "Server time : "; date
lastlog | grep “root” | awk {‘print “Last login from : “$3
print “Last Login Date & Time: “,$4,$5,$6,$7,$8,$9;}’
During start up, you will get the message as shown below.
login as: root root@dev-db's password: Welcome on dev-db
Kernel Information: Linux 2.6.18-128 x86_64 GNU bash, version 3.2.25(1)-release (x86_64-redhat-linux-gnu) Copyright (C) 2005 Free Software Foundation, Inc. Uptime: 11:24:01 up 21 days, 13:15, 3 users, load average: 0.08, 0.18, 0.11 Server time : Tue Feb 22 11:24:01 CET 2010
Last login from : sasikala-laptop
Last Login Date & Time: Tue Feb 22 11:24:01 +0100 2010
Example 5. Export variables and set aliases during start-up
The most common commands you will use in your .bashrc and .bash_profile files are the export and alias command.
An alias is simply substituting one piece of text for another. When you run an alias, it simply replaces what you typed with what the alias is equal to. For example, if you want to set an alias for ls command to list the files/folders with the colors, do the following:
alias ls 'ls --color=tty'
If you add this command to one of the start-up files, you can execute ls command, where it will be automatically replaced with the ls –color=tty command.
Export command is used to set an environment variable. Various environment variables are used by the system, or other applications. They simply are a way of setting parameters that any application/script can read. If you set a variable without the export command, that variable only exists for that particular process.
In the example below, it is exporting the environment variable HISTSIZE. The line which is starting with # is a comment line.
$ cat /etc/profile
alias ls 'ls --color=tty'
# Setup some environment variables.
export HISTSIZE=1000
PATH=$PATH:$HOME/bin:/usr/bin:/bin/usr:/sbin/etc
export PATH
export SVN_SH=${SVN_RSH-ssh}
Writing a Simple Bash Script
The first step is often the hardest, but don’t let that stop you. If you’ve ever wanted to learn how to write a shell script but didn’t know where to start, this is your lucky day.
If this is your first time writing a script, don’t worry — shell scripting is not that complicated. That is, you can do some complicated things with shell scripts, but you can get there over time. If you know how to run commands at the command line, you can learn to write simple scripts in just 10 minutes. All you need is a text editor and an idea of what you want to do. Start small and use scripts to automate small tasks. Over time you can build on what you know and wind up doing more and more with scripts.
Starting Off
Each script starts with a “shebang” and the path to the shell that you want the script to use, like so:
#!/bin/bash
The “#!” combo is called a shebang by most Unix geeks. This is used by the shell to decide which interpreter to run the rest of the script, and ignored by the shell that actually runs the script. Confused? Scripts can be written for all kinds of interpreters — bash, tsch, zsh, or other shells, or for Perl, Python, and so on. You could even omit that line if you wanted to run the script by sourcing it at the shell, but let’s save ourselves some trouble and add it to allow scripts to be run non-interactively.
What’s next? You might want to include a comment or two about what the script is for. Preface comments with the hash (#) character:
#!/bin/bash # A simple script
Let’s say you want to run an rsync command from the script, rather than typing it each time. Just add the rsync command to the script that you want to use:
#!/bin/bash # rsync script rsync -avh --exclude="*.bak" /home/user/Documents/ /media/diskid/user_backup/Documents/
Save your file, and then make sure that it’s set executable. You can do this using the chmod utility, which changes a file’s mode. To set it so that a script is executable by you and not the rest of the users on a system, use “chmod 700 scriptname” — this will let you read, write, and execute (run) the script — but only your user. To see the results, run ls -lh scriptname and you’ll see something like this:
-rwx------ 1 jzb jzb 21 2010-02-01 03:08 echo
The first column of rights, rwx, shows that the owner of the file (jzb) has read, write, and execute permissions. The other columns with a dash show that other users have no rights for that file at all.
Variables
The above script is useful, but it has hard-coded paths. That might not be a problem, but if you want to write longer scripts that reference paths often, you probably want to utilize variables. Here’s a quick sample:
#!/bin/bash # rsync using variables SOURCEDIR=/home/user/Documents/ DESTDIR=/media/diskid/user_backup/Documents/ rsync -avh --exclude="*.bak" $SOURCEDIR $DESTDIR
There’s not a lot of benefit if you only reference the directories once, but if they’re used multiple times, it’s much easier to change them in one location than changing them throughout a script.
Taking Input
Non-interactive scripts are useful, but what if you need to give the script new information each time it’s run? For instance, what if you want to write a script to modify a file? One thing you can do is take an argument from the command line. So, for instance, when you run “script foo” the script will take the name of the first argument (foo):
#!/bin/bash echo $1
Here bash will read the command line and echo (print) the first argument — that is, the first string after the command itself.
You can also use read to accept user input. Let’s say you want to prompt a user for input:
#!/bin/bash echo -e "Please enter your name: " read name echo "Nice to meet you $name"
That script will wait for the user to type in their name (or any other input, for that matter) and use it as the variable $name. Pretty simple, yeah? Let’s put all this together into a script that might be useful. Let’s say you want to have a script that will back up a directory you specify on the command line to a remote host:
#!/bin/bash echo -e "What directory would you like to back up?" read directory DESTDIR= user@host.rsync.net:$directory/ rsync --progress -avze ssh --exclude="*.iso" $directory $DESTDIR
That script will read in the input from the command line and substitute it as the destination directory at the target system, as well as the local directory that will be synced. It might look a bit complex as a final script, but each of the bits that you need to know to put it together are pretty simple. A little trial and error and you’ll be creating useful scripts of your own.