Most simply, a boot loader loads the operating system. When your machine loads its operating system, the BIOS reads the first 512 bytes of your bootable media (which is known as the master boot record, or MBR). You can store the boot record of only one operating system in a single MBR, so a problem becomes apparent when you require multiple operating systems. Hence the need for more flexible boot loaders.
The master boot record itself holds two things — either some of or all of the boot loader program and the partition table (which holds information regarding how the rest of the media is split up into partitions). When the BIOS loads, it looks for data stored in the first sector of the hard drive, the MBR; using the data stored in the MBR, the BIOS activates the boot loader.
Due to the very small amount of data the BIOS can access, most boot loaders load in two stages. In the first stage of the boot, the BIOS loads a part of the boot loader known as the initial program loader, or IPL. The IPL interrogates the partition table and subsequently is able to load data wherever it may exist on the various media. This action is used initially to locate the second stage boot loader, which holds the remainder of the loader.
The second stage boot loader is the real meat of the boot loader; many consider it the only real part of the boot loader. This contains the more disk-intensive parts of the loader, such as user interfaces and kernel loaders. These user interfaces can range from a simple command line to the all-singing, all-dancing GUIs.
Boot loaders are usually configured in one of two ways: either as a primary boot loader or as a secondary boot loader. Primary boot loaders are where the first stage of the boot loader is installed on the MBR (per the previous description). Secondary boot loaders are where the first stage of the boot loader is installed onto a bootable partition. A separate boot loader must then be installed into the MBR and configured to pass control to the secondary boot loader.
Many newer Linux boot loaders can be especially useful since they give you varying degrees of interaction, such as advanced GUI and encrypted passwords, along with the ability to load from a selection of operating systems. Thus you can have many operating systems coexisting on the same machine spanning multiple physical disks. This setup has become common because it helps many users reconcile the treasures of valuable datafiles originally generated by their Windows® machines with their shiny new Linux installs. Personally, I think this setup is great; I use a single box for both Linux and Windows.
Over time, boot loaders have been enhanced to include a greater range of functionality for the user. Such functionality and configuration vary from loader to loader, although the basic purpose remains the same.
Now let’s look at two of the more popular boot loaders: LILO and GRUB.
LILO
LInux LOader, or LILO, comes as standard on all distributions of Linux. As one of the older/oldest Linux boot loaders, its continued strong Linux community support has enabled it to evolve over time and stay viable as a usable modern-day boot loader. Some new functionality includes an enhanced user interface and exploitation of new BIOS functions that eliminate the old 1024-cylinder limit.
Although LILO continues to be developed, the basic principles of how LILO works still remain the same.

Making LILO your boot loader
What you will need to do to use LILO as your boot loader depends on whether you are installing the OS fresh or have already installed Linux and are planning on moving to LILO. If you’re starting fresh, you can jump straight to the Configuring LILO section. If you already have a Linux distribution installed, you usually get an option to install and configure LILO (and can boot your machine into your new Linux install).
For existing Linux users migrating to LILO, first you have to acquire the latest version of LILO. Before doing anything else, I advise you to make sure you have a Linux boot disk handy — it makes life a lot easier if you accidentally mess something up and would like to be able to get back into your original Linux configuration! Once you have LILO on your system, making it take over your MBR is very easy. As the root user, type:
# /sbin/lilo -v -v
This will use the current LILO defaults and splat anything that is currently in the MBR. However, read about Configuring LILO to make sure you are able to boot up as expected. Also note that if you want to run Windows and Linux on a single machine, you should install your Windows OS first and then the Linux OS, so that the boot loader you choose in the Linux install won’t be written over by the Windows boot loader. Unlike the Linux boot loaders, the majority of Windows boot loaders will not allow you to load Linux. If you’ve already installed Linux first, don’t fret; just create yourself a Linux boot disk so that after you have installed Windows, you can get back into your Linux install and overwrite the MBR.
Configuring LILO
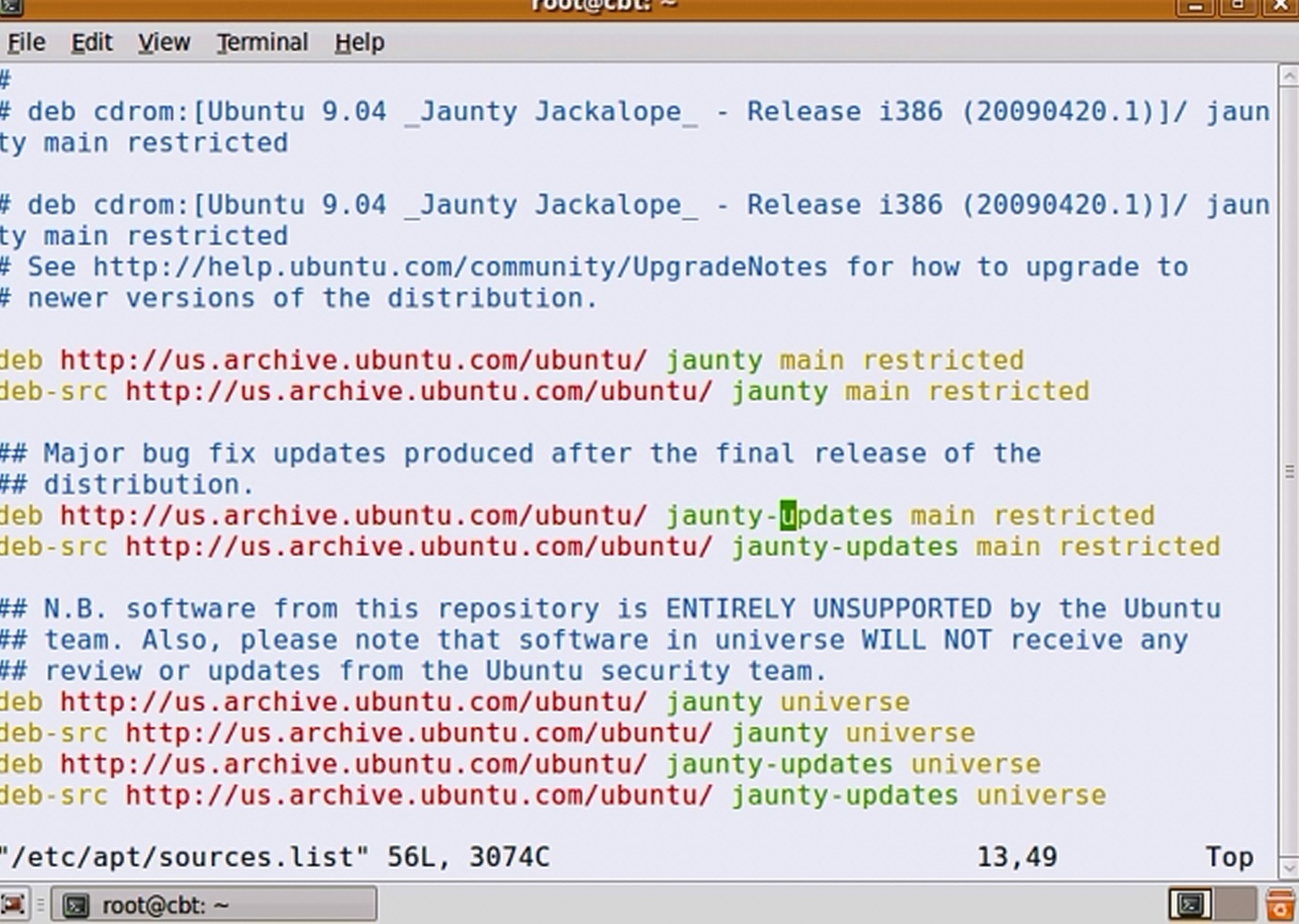
LILO configuration is all done through a configuration file located in /etc/lilo.conf. Listing 1 shows an example configuration, relating to my home machine, for dual booting a Linux and Windows machine. You can visualize how this configuration relates to an actual machine by looking at my basic workstation setup:
- Primary HDD (physical disk 1) with Windows XP installed (initially all there was on the machine). In Linux terms, this HDD is /dev/hda (hd0,0 in GRUB terms).
- Secondary HDD (physical disk 2) with Red Hat Linux installed; the root partition is on the third partition of this hard drive, /dev/hdb3 (hd1,2 in GRUB terms).
Listing 1. Example lilo.conf file
boot=/dev/hda
map=/boot/map
install=/boot/boot.b
prompt
timeout=100
compact
default=Linux
image=/boot/vmlinuz-2.4.18-14
label=Linux
root=/dev/hdb3
read-only
password=linux
other=/dev/hda
label=WindowsXP
The options used in Listing 1 are:
- The
boot= line tells LILO where to install the boot loader. In the previous example, this will install it to the MBR of first hard disk. You could alternatively install LILO in /dev/hdb3 (the Linux partition in the example), which would then require you to install another boot loader into /dev/hda that points it to the LILO boot loader; then you just let LILO act as a secondary boot loader. In general, /dev/hda is the most common place for your boot loader to reside. You can also make a LILO floppy boot disk by pointing this parameter to the floppy drive, most commonly /dev/fd0.
map= points to the map file used by LILO internally during bootup. When you install LILO using the /sbin/lilo command, it automatically generates this file, which holds the descriptor table (among other things). My advice is to leave this as it is!install= is one of the files used internally by LILO during the boot process. This holds both the primary and secondary parts of the boot loader. A segment of this boot.b file is written to the MBR (the primary part of the boot loader), which then points to the map and subsequently points to the secondary boot loader. Again, leave this as it is!prompt= tells LILO to use the user interface (giving you in this example two selections — Linux and WindowsXP). In addition using the prompt/user interface, you get the option to specify specific parameters for the Linux kernel or others if appropriate. If you do not specify this option in the configuration file, LILO will boot into the default OS with no user interaction and no waiting. (It’s worth noting, though, that if you hold the SHIFT key down during boot, you can get the prompt up anyway, which is quite useful if you don’t want the average Joe to be exposed to the boot loader).timeout= is the number of tenths of a second that the boot prompt will wait before automatically loading the default OS, in this case Linux. Ifprompt is not specified in the lilo.conf, this parameter is ignored.- The
compact option magically makes the boot process quicker by merging adjacent disk read requests into a single request. It can be a mixed blessing, though, as I’ve seen a number of posts on forums regarding issues with this option. This option especially useful if you wish to boot from a floppy.
- The
default= option tells LILO which image to boot from by default, such as after the timeout period. This relates to a label of one of the images in the lilo.conf file. If you don’t specify this option in the configuration file, it will boot the first image specified in the file.
- For each version of Linux you want to make available for users to boot into, you should specify
image= and the following three options. The image option specifies the kernel version you wish to boot to.
label= identifies the different OS you want to boot from at the user interface at runtime. In addition, this label is used for specifying the default OS to boot from. (Note: Avoid spaces in the label name; otherwise, you will get an unexpected error when loading the file.)- The
root= option tells LILO where the OS file system actually lives. In our example, it is /dev/hdb3, which is the third partition of the second disk.
read-only tells LILO to perform the initial boot to the file system read only. Once the OS is fully booted, it is mounted read-write.- The
password= option allows you to set a password for the specific OS you are booting into. In the example this password is held in the lilo.conf file as readable text, so is easily accessible for all to read. Alternatively if you set password=”” you can set the password when the bootloader is installed. These can be set on each of the operating systems you wish to boot from if required (in our example we only set a password on the Linux boot).
other= acts like a combination of the image and root options, but for operating systems other than Linux. In our example, it tells LILO where to find the Windows OS, which resides on the first disk in the first partition. This will usually be the case if you have installed Windows first, then Linux.label= is the same as all other label options.
You can use many other parameters in the lilo.conf file, but the parameters in Listing 1 should get you into a fairly usable state on your machine. For further information on these and other lilo.conf parameters, refer to the manual pages (man lilo.conf). Since lilo.conf is not read at boot time, the MBR needs to be “refreshed” when this is changed. If you do not do this upon rebooting, none of your changes to lilo.conf will be reflected at startup. Like getting LILO into the MBR in the first place, you need to run:
$ /sbin/lilo -v -v
The -v -v flags give you very verbose output. There are a fair number of parameters you can specify when running LILO like we did. See the manual pages for further information (man lilo).
The initial boot process
When LILO initially loads, it brings up in order each of the letters — L-I-L-O. If all the letters come up, the first stage boot was successful. Anything less indicates a problem:
- L: The first stage boot loader has been loaded. If LILO stops here, there were problems loading the second stage boot loader. This is usually accompanied by an error code. The common problems at this stage are media problems or incorrect disk parameters specified in your lilo.conf file.
- LI: The second stage boot loader has been loaded. LILO halting at this point indicates the second stage boot loader could not be executed. Again, this can be due to problems similar to just L: loading or if the boot.b file has been corrupted, moved, or deleted.
- LIL: The second stage boot loader has now been executed. At this point, media problem could again be responsible or the map file (as specified in the lilo.conf file) could have had problems finding the descriptor tables.
- LIL?: Loaded to the same point as above. This usually means the second stage boot loader loaded at an incorrect address, caused most likely by boot.b being in a different place than specified in the lilo.conf file.
- LIL-: Loaded to the same point as above. Problem loading the descriptor table, most likely due to a corrupt descriptor table.
- LILO: LILO has successfully loaded with no errors.
Additional configuration at boot time
Once LILO has successfully loaded, you will see a LILO prompt. Still using the example lilo.conf file as before, at this point you have two choices, which may not be immediately obvious to LILO newbies. First, you may let LILO time out (after 10 seconds), which will boot /dev/hdb3, the Linux partition. Second, you can press the TAB key, which will list a selection of operating systems to boot from. In our example lilo.conf, we would get “Linux” and “WindowsXP” as our options. Typing either of these will load up that OS. Specifically loading the Linux option will then prompt you to enter a password, which in this case is linux. Incorrectly entering the password will take you back to the LILO prompt.
A final word of advice when trying out LILO for the first time: I found it a lot safer to work out my LILO configuration using a floppy boot disk rather than my hard disk. To do this, you must replace the boot=/dev/hda with boot=/dev/fd0 in the lilo.conf file. That way, if I messed up any of the configuration in my lilo.conf file, I could take out the boot disk and boot into Linux as before. Once I was happy everything booted fine using the floppy disk, I then changed my lilo.conf back to use boot=/dev/hda and ran /sbin/lilo a final time to upload my changes.
GNU GRUB


More recently, the GRand Unified Boot loader (commonly known as GRUB) seems to have somewhat taken the boot loaders crown from LILO. GNU GRUB is actively developed by the Free Software Foundation and based on the original GRUB program, originally created by Erich Stefan Boleyn.
Make GRUB your boot loader
As with LILO, the steps you will need to perform to use GRUB as your active boot loader depend on whether you are installing the OS fresh or have already installed Linux and are planning on moving to GRUB. If you’re starting fresh, you can jump straight to the Configuring GRUB section. If you already have a Linux distribution installed, you usually get an option to install and configure LILO (and can boot your machine into your new Linux install).
For existing Linux users wanting to migrate to GRUB, get the latest version of GRUB (see Resources). Again, as with LILO, before doing anything else, have a Linux boot disk handy. With the interactive mode (described below), this disk should not be required, but it’s nice to have just in case you get out of your depth. Once you have GRUB installed on your system, making it take over your MBR is easy. As the root user, type:
# /boot/grub/grub
This will load up a BASH-like command prompt where you now use the GRUB command:
grub> install (hd1,2)/boot/grub/stage1 (hd1) (hd1,2)/boot/grub/stage2 p (hd1,2)/boot/grub/menu.conf
This command uses the GRUB install command, which requires the location of the stage one image and the location of the MBR (install (hd1,2)/boot/grub/stage1 (hd1)). Also the location of the stage two image ((hd1,2)/boot/grub/stage2) is required. Finally, an optional p (hd1,2)/boot/grub/menu.conf tells GRUB the location of the GUI menu configuration file.
In the previous example, hd1 is my Linux Disk and hd0 is my Windows disk. This will use the current GRUB defaults and splat anything that is currently in the MBR (read Configuring GRUB to make sure you are able to boot up as expected).
Configuring GRUB
GRUB configuration is all done through a configuration file located in /boot/grub/grub.conf. Listing 2 shows an example configuration that relates to my home setup, a dual-booting Linux and Windows machine:


Listing 2. Example grub.conf file
default=0
timeout=10
splashimage=(hd1,2)/grub/splash.xpm.gz
password --md5 $1$opeVt0$Y.br.18LyAasRsGdSKLYlp1
title Red Hat Linux
password --md5 $1$0peVt0$Y.br.18LyAasRsGdSKLYlp1
root (hd1,2)
kernel /vmlinuz-2.4.18-14 ro root=LABEL=/
initrd /initrd-2.4.18-14.img
title Windows XP
password --md5 $1$0peVt0$Y.br.18LyAasRsGdSKLYlp1
rootnoverify (hd0,0)
chainloader +1
The options used in Listing 2 are:
- The
default= option signals to GRUB which image to boot from by default after the timeout period. This relates to one of the images in the grub.conf file. 0 is the first specified, 1 is the second specified, etc. If you don’t specify this option in the configuration file, it will boot the first image specified in the file.
timeout= is the number of seconds the boot prompt will wait before automatically loading the default OS, in this case, Red Hat Linux.splashimage= is the location of the image to be used as the background for the GRUB GUI.- The
password option specifies the MD5-encrypted password used to gain access to GRUB’s interactive boot options. Note this does not stop users loading your defined OS choices; this needs to be set on a per-title basis. To generate an md5 password, run the tool grub-md5-crypt (as root), which comes with GRUB. It will prompt you for the password you want to encrypt. It then will output the MD5-encrypted password. Copy this into your grub.conf after password -md5 but on the same line. Usually this password can be set to the root password, since it is only root who can read the grub.conf file anyway.
title identifies the specific OS that will be booted from at the user interface at runtime. Unlike with LILO, you can include spaces in this name.password is set in the same way as the password above. Do not set this password to the root password if you are planning on sharing this machine with other users.- The
root option tells GRUB where the OS file system actually lives. As you can see, GRUB references the media in a different way than LILO. In our LILO example, /dev/hdb3 is the third partition of the second disk. Grub references this disk as (hd1,2), again the third partition of the second disk (disk 0 being the first disk, partition 0 being the first partition).
kernel: vmlinuz-X.X.XX-XX is the name of the default boot kernel image within your root directory.initrd: initrd-X.X.XX-XX.img is the name of the default initrd file within your root directory.title is the same as all other title options.password: See other password options.- The
rootnoverify option tells GRUB to not try to vary the root of the OS. This saves load errors if the file system is not a supported by GRUB.
chainloader +1 tells GRUB to use a chain loader to load this OS, which is required for loading Windows.
You can use many other parameters in the grub.conf file, but the parameters in Listing 2 should get you into a fairly usable state on your machine. For further information on these and other grub.conf parameters, see the manual pages (man grub.conf).
Unlike LILO’s configuration file, grub.conf is read at boot time, and the MBR does not need to be refreshed when this is changed.
The initial boot process
When GRUB initially loads, like LILO it loads its first stage from the MBR. Once this has loaded, it then enters an intermediate stage between the common boot loader stages one and two (or for argument’s sake, Stage 1.5). Stage 1.5 is present to enable regular file system access to the GRUB configuration files in /boot/grub rather than accessing using disk blocks. We then enter stage two of the boot loader where GRUB loads the grub.conf file.
You should now see the GRUB GUI. For any native Windows user, this seems a much more friendly experience than that of LILO. But don’t think by having a GUI that GRUB is a dumbed-down boot loader. The wealth of options is astonishing. (See the tips for additional configuration at boot time.)
If your configuration is like mine, you should now be looking at a screen giving you two options: to boot into Red Hat Linux or to boot into Windows XP. By default, it will load Linux. The result of selecting either one of these is self explanatory.
Now for the good stuff.
Additional configuration at boot time
At the GRUB GUI, pressing any key will stop the timeout from kicking in. Then by pressing the P key, you can enter your GRUB password and gain full access to GRUB’s interactive booting options. You should now be able to use one of the three options by pressing the one of the following keys:
- For edit commands before booting, press E. This allows you to edit the specific options for the currently highlighted OS. GRUB will then show only the options specific to the booting of that OS, which you can then edit as you see fit. This is especially useful if you have specified the wrong HDD for the root file system. If you need to access the machine in single-user mode (giving you root access without specifying a password!), select the Linux OS at the GRUB main screen. Then as before, press E and move to the kernel line (in my example, this is
kernel /vmlinuz-2.4.18-14 ro root=LABEL=/). You then append single to the end of this line, and press B to boot using your changed grub.conf. Any changes you make in edit mode are not saved to the grub.conf file.
- To modify kernel arguments, press A. If you are an experienced Linux user, you can tweak the kernel arguments to suit your needs.
- To get to a BASH-like command-line interface, press C. This minimal command-line interface allows you to find GRUB configuration files on your system, load an alternate configuration file, and edit lines in the configuration file, as well as enter GRUB commands directly. You might use this if a configuration change, such as deleting a partition, has made your system unbootable. You might also use it if you need to boot a system into single-user mode or perhaps runlevel 3 instead of your normal runlevel.
The many uses for these options are beyond the scope of this article.
As you can see, GRUB really opens up the possibilities at boot time. This can be a mixed blessing, though, as GRUB also potentially allows attackers to gain access to the system before the OS has loaded. The main areas open to misuse are:
- Access to single-user mode. Anyone loading into single-user mode is given root access, leaving your Linux system wide open to abuse.
- Access to other operating systems. Any bootable operating systems you have configured that do not require a password, such as DOS, will be open.
- Access to the GRUB editor. This allows users full access to change the GRUB configuration.
Setting security plays an important part in your GRUB configuration; setting a password and using MD5 encryption pays dividends to your overall system security.
Future of GRUB
GRUB is now being replaced by GRUB2. The original GRUB is being renamed to GRUB Legacy; apart from fixing bugs, it will no longer be actively developed. GRUB2 will be a complete rewrite of the original boot loader. To date, the following features are the core of the changes:
- Replacement of Stage 1.5 with the creation of a compact core image
- Support for dynamic loading to the core image
- Trend towards making the overall GRUB framework object oriented
- Support for internationalization, such as non-ASCII character sets
- Support for different hardware architectures and different platforms (other than Linux)
Refer to the GRUB Web site (see the Resources section below for the latest developments.
GRUB vs. LILO
As stated at the start of this article, all boot loaders work in a similar way to fulfill a common purpose. But LILO and GRUB do have a number of differences:
- LILO has no interactive command interface, whereas GRUB does.
- LILO does not support booting from a network, whereas GRUB does.
- LILO stores information regarding the location of the operating systems it can to load physically on the MBR. If you change your LILO config file, you have to rewrite the LILO stage one boot loader to the MBR. Compared with GRUB, this is a much more risky option since a misconfigured MBR could leave the system unbootable. With GRUB, if the configuration file is configured incorrectly, it will simply default to the GRUB command-line interface.
Conclusion
As with all software, the best choice for one user isn’t always the best for all. Of the two boot loaders covered here, my personal favorite is GNU GRUB. It is a good all-around loader, combining a slick user interface with a wealth of functionality. And yet many people who have used and loved LILO still find it to be the boot loader of choice. Fortunately, if you are new to the world of Linux boot loading, you won’t go far wrong with either.
Regarding security, anyone with access to a boot disk/CD can get past any of the security measures mentioned in this article by simply booting using a grub.conf or lilo.conf that does not have security set. With GRUB in particular, being able to boot into single-user mode could pose a serious security hole. A simple way to get around this problem is to disable booting from CD and floppy in your machine’s BIOS and make sure your BIOS is set with a password so others can not change these settings.
Have fun!
GRUB bootloader – Full tutorial
One of the most frightening things about Linux is the horrible word bootloader. The primary reason for this is the fact that most new Linux users have only ever used Windows operating systems. In the Windows world, they have never bothered with bootloaders. For them, the issue of a system booting was a transparent one. At most, they would use Windows Recovery Console to fix problems for them. Thus, they have been spared the need to learn about the single most important piece of software on a computer – the little program that makes it all work.
This article is supposed to provide you with basic understanding of the GRUB bootloader. If you have read my other Linux articles, you are familiar with partitioning and Linux notation, as well as with the command line. The next logical step is to enhance this knowledge by taking one step further. Understanding how GRUB works and what boot entries in the boot menu mean will help you understand how the operating systems work, how to fix, recover or modify the GRUB menu to suit your needs, and how to setup different work environments with several operating systems.
In the past, we have relied on the installation setups to make the hard work for us. In fact, setting up GRUB, while frightening, is a quite simple and fully reversible procedure. Mastering the GRUB is a very important step in building up the confidence to use Linux. So if you are ready, read on.
But first of all, a foreword of wisdom. This article is a compilation of sources and examples that will help you learn about GRUB. Of course, it’s all out there somewhere, on the Internet. However, new Linux users will probably find the notion of spending hours searching for relevant pieces of information (especially if their PC won’t boot) somewhat frustrating. The goal of this guide is to help provide simple and quick solutions to most common problems regarding multi-boot setups and installation of Linux operating systems.
Everything is a file
To be able to successfully master the secrets of GRUB, you must understand one of the basic foundations of *NIX-based operating systems. Everything is a file. Even hard disks and partitions are treated as files. There is no magic. If you remember this, you will find the supposedly perilous task of tampering with partitions no different than playing with files using a file explorer (or the command line). Now that we have established this, we can move on to the more technical parts of grubbing.
Introduction
GNU GRUB is a bootloader (can also be spelled boot loader) capable of loading a variety of free and proprietary operating systems. GRUB will work well with Linux, DOS, Windows, or BSD. GRUB stands for GRand Unified Bootloader.
GRUB is dynamically configurable. This means that the user can make changes during the boot time, which include altering existing boot entries, adding new, custom entries, selecting different kernels, or modifying initrd. GRUB also supports Logical Block Address mode. This means that if your computer has a fairly modern BIOS that can access more than 8GB (first 1024 cylinders) of hard disk space, GRUB will automatically be able to access all of it.
GRUB can be run from or be installed to any device (floppy disk, hard disk, CD-ROM, USB drive, network drive) and can load operating systems from just as many locations, including network drives. It can also decompress operating system images before booting them.
What about LILO?
You may have heard about another Linux bootloader called LILO (stands for LInux LOader). While a sensible option for many Linux users, I believe that GRUB is a better choice, for several reasons:
- LILO supports only up to 16 different boot selections; GRUB supports an unlimited number of boot entries.
- LILO cannot boot from network; GRUB can.
- LILO must be written again every time you change the configuration file; GRUB does not.
- LILO does not have an interactive command interface.
All in all, it seems that GRUB is the winner. So let’s see what this baby can do.
How does GRUB work?
When a computer boots, the BIOS transfers control to the first boot device, which can be a hard disk, a floppy disk, a CD-ROM, or any other BIOS-recognized device. We’ll concentrate on hard disks, for the sake of simplicity.
The first sector on a hard is called the Master Boot Record (MBR). This sector is only 512 bytes long and contains a small piece of code (446 bytes) called the primary boot loader and the partition table (64 bytes) describing the primary and extended partitions.
By default, MBR code looks for the partition marked as active and once such a partition is found, it loads its boot sector into memory and passes control to it.
GRUB replaces the default MBR with its own code.
Furthermore, GRUB works in stages.
Stage 1 is located in the MBR and mainly points to Stage 2, since the MBR is too small to contain all of the needed data.
Stage 2 points to its configuration file, which contains all of the complex user interface and options we are normally familiar with when talking about GRUB. Stage 2 can be located anywhere on the disk. If Stage 2 cannot find its configuration table, GRUB will cease the boot sequence and present the user with a command line for manual configuration.
Stage 1.5 also exists and might be used if the boot information is small enough to fit in the area immediately after MBR.
The Stage architecture allows GRUB to be large (~20-30K) and therefore fairly complex and highly configurable, compared to most bootloaders, which are sparse and simple to fit within the limitations of the Partition Table.
GRUB notation
This section is intended to help you get familiar with GRUB, without touching anything. The next section deals with actual files and manual configuration. GRUB has its own notation, which is very similar yet somewhat different from the general notation a typical Linux user might be used to. Now, here’s an example of a typical GRUB entry:
(hd0,1)
- The brackets are a must; all devices listed in GRUB menu must be enclosed in brackets.
- hd stands for hard disk; alternatively, fd stands for floppy disk, cd stands for CD-ROM etc.
- The first number (integer for geeks) refers to the physical hard drive number; in this case, the first drive, as they are counted from zero up. For example, hd2 refers to the third physical hard drive.
- The second number refers to the partition number of the selected hard drive; again, partitions are counted from zero up. In this case, 1 stands for the second partition.
From here, it is evident that GRUB (menu) does not discriminate between IDE or SCSI drives or primary or logical partitions. The task of deciding which hard drive or partition may boot is left to BIOS and Stage 1. As you see, the notation is very simple.
Primary partitions are marked from 0 to 3 (hd?,0), (hd?,1), (hd?,2), (hd?,3). Logicalpartitions in the extended partition are counted from 4 up, regardless of the actual number of primary partitions on the hard disk, e.g. (hd1,7).
The entries alone are not enough to boot an operating system though. GRUB also needs to know what operating system images to load. These are assigned as parameters to each of the called devices, including special flags (switches). For example, Windows Safe Mode is a special flag. Here is an example of a GRUB menu booting only Ubuntu.

Here’s an example of a GRUB menu from a computer with triple boot (SUSE 10.2, Ubuntu 6.10 and Windows XP). This is the actual menu.lst on one of my real machines.

Let’s try to understand what the entries mean. Only uncommented lines count. Commentsare marked with #. The lines that have a series of small gray xs showing are in indication that text therein belongs to the line preceding it. In other words, there text simply dropped to another line to visually accommodate the text editor and screen resolution limitations.
default 0
timeout 8
The first line (default 0) means that the first operating system listed will be booted. In this case, it’s SUSE 10.2. The second line (timeout 8) tells how much time (seconds) the user has to make his choice before the default entry is loaded. Simple, isn’t it?
gfxmenu (hd0,2)/boot/message
The GRUB menu can also be graphic. The fancy stuff needed to present the user with a colorful background and possibly some extras is located on the first physical disk, thirdpartition (hd0,2). This is a primary partition, as we have seen earlier.
title openSUSE 10.2
root (hd0,2)
kernel /boot/vmlinuz-…
initrd /boot/initrd.img-…
This is the first operating system entry in the menu.
- title is as simple as it sounds. It’s merely a string that’s meant to help the user read the menu in human terminology.
- root (hd0,2) tells GRUB where its configuration files are located. In this instance, they can be found under (hd0,2)/boot/grub.
- kernel /boot/vmlinuz-… boots the actual kernel image. There can be many such images available. The fact there is no device specified before the /boot/vmlinuz indicates the image is located on the same partition as the GRUB itself. This is often the default case for your primary choice of operating system.
- initrd /boot/initrd.img-… is the temporary file system that makes system preparations – adapts generic kernel image to specific hardware – before the real root is loaded.
The extra switches used after the kernel indicate where the actual root is located, what graphic mode is used and where the swap partition resides. This article will not go into detail regarding the more advanced GRUB configurations.
title Ubuntu, kernel … (/dev/sda9)
kernel (hd0,8)/boot/vmlinuz-…
initrd (hd0,8)/boot/initrd.img-…
- Again, title indicates a name, in this case fancily adorned with technical details.
- kernel (hd0,8)/boot/vmlinuz-… points to the 9th partition on the first hard disk (hd0,8). Accidentally, the root flag (/dev/sda9) indicates that the root partition is the same as the one containing the kernel image. Normally, this is the case, and for the sake of simplicity, you will want this option during your installations.
- initrd (hd0,8)/boot/initrd.img-… nothing new here.
Note regarding kernel images and root partitions: On older computers with BIOS that do not support access to more than the first 1024 cylinders, you might setup a boot partition that contains the kernel image, while the root itself is located elsewhere. But people with computers younger than the botched Y2K crisis need not worry.
Another thing you might notice is that the Ubuntu entry is fairly detailed. This feature is called Multi-boot Compliance; openSUSE recognizes Ubuntu and can accurately call its images (including special switches) and mount the partitions. However, most operating systems are only partially multi-boot compliant. A little later on, I will show you how the Ubuntu entry could have been treated differently, with the same results.
title Windows
rootnoverify (hd0,0)
chainloader (hd0,0)+1
- rootnoverify (hd0,0) means that openSUSE cannot understand Windows operating system, i.e. no multi-boot compliance. Therefore, the operating system is called without any fore-knowledge of the kernel. GRUB assumes that the relevant boot images will be found on the target partition and mounted by the other operating system bootloader. As you can see, Windows was installed on the first partition of the first hard disk. This is the most convenient option.
- chainloader (hd0,0)+1 feature is used for operating systems that cannot be booted directly. Not surprisingly, Windows operating systems cannot be booted directly. They are booted by the method of chainloading. As the name implies, GRUB passes the control of the boot sequence to another bootloader, located on the device to which the menu entry points. This can be a Windows operating system, but also any other, including Linux.
Back to Ubuntu. You remember that I have told we could have booted Ubuntu in an alternative way? Indeed, we could have simply chainloaded it, just like Windows.
title Ubuntu
root (hd0,8)
chainloader (hd0,8)+1
This would have worked equally well. The last option in the menu allows you to boot SUSE in the failsafe mode (sort of Safe Mode, no graphics) and does not contribute to our knowledge, therefore we will skip it at the moment. Let’s see some more examples. The example below is actually written in the Ubuntu menu.lst (commented, of course).
title Windows 95/98/NT/2000
root (hd0,0)
makeactive
chainloader +1
title Linux
root (hd0,1)
kernel /vmlinuz root=/dev/hda3 ro
By now, you should be able to “read” GRUB language with ease. We begin with the title. rootspecifies the partition where we expect to find the Windows kernel and mounts it (rootnoverify would leave this job to the Windows bootloader). makeactive command sets the active partition on the root disk (above) to GRUB root device. This means that the next command, chainloader, is executed without the target partition specified (as the target partition is the same, now).
The second entry is even simpler. We name a Linux, we call its partition and we boot the kernel. In this case, we see the very interesting case where the kernel image and root (/) partition of the operating system are NOT located on the same partition. This would be a very likely case for older computers – or ones with a specific boot partition.
You see, it’s very simple! Once you get the hang of it, it actually becomes fun.
GRUB configuration
Most of the time, you will not want or need to touch GRUB. When you install operating systems, especially in the right sequence (inconsiderate OS first – like Windows, flexible OS later – Linux and family), the GRUB will be installed automatically and relevant entries appended.
Nevertheless, you should know when and what to do if things go wrong.
Installation of GRUB
GRUB can be installed to a variety of devices. Most people will be interested in setting up GRUB on their hard disk. Nevertheless, it does not hurt to know learn about other options. Of course, you can skip forward. Before we install anything, we need to know where our files are. If installed, GRUB menu is located on the root partition under:
/boot/grub/menu.lst
Always, always back this file up before making any changes! The GRUB files can be found in the image of your operating system (usually a CD), under:
/usr/lib/grub/i386-pc
You should also be aware of the basic Linux commands regarding the hard disks and partitions. To this end, you might want to try my article Highly useful Linux commands & configurations. Nevertheless, for those who do not fancy reading yet another article, here’s a brief version:
You can display your PC environment information either through terminal or a text editor. Files through text editor are invoked by specifying the text editor and a target file (with su or sudo for system files).
sudo vi /etc/fstab
OR
sudo gedit /etc/fstab
Alternatively, you can simply print the contents of the files in the terminal by using the cat(concatenate) command.
(sudo) cat /etc/fstab
Some useful commands that one might need when dealing with boot, hard drives and partitions: Display the partition table:
fdisk -l
Display the mounted partitions:
cat /etc/fstab
Now that we know what we need and where to find it, it’s time to install GRUB.
GRUB on a floppy disk
To create GRUB on a floppy disk, we must copy the Stage 1 and Stage 2 files from the image directory to the first and second sector of the floppy disk. We’ll use the dd command, which copies information sector by sector. Here’s the set of commands that you need to execute (taken from the Manual):
cd /usr/lib/grub/i386-pc
dd if=stage1 of=/dev/fd0 bs=512 count=1
dd if=stage2 of=/dev/fd0 bs=512 seek=1
Just a short explanation: if stands for input file, of stands for output file, /dev/fd0 refers to the first mounted floppy device, bs specifies the block size (in bytes), count instructs how many blocks should be copied, and seek tells how many blocks should be skipped before writing. Not surprisingly, since we need to write the files to the first two sectors of the floppy disk, we write stage1 to the first sector, and copy stage2 to the second (skip first, then write). Now that we have taken this deep fancy for the command line, I’ll leave you with the nuances of different commands for homework.
Regarding the GRUB on floppy, that’s it. Since we have copies the stages from OS image, all of the required information is there. Of course, you can always make manual adjustments. But that’s the next chapter.
Installing GRUB natively
Native install means placing GRUB Stage 1 in the first sector of the hard disk (MBR orPartition Table). This means you will be able to boot without a secondary device, like a floppy disk (which have become a rarity nowadays). However, this also means that if you install an inconsiderate OS later on (like Windows) or try to repair the MBR for some reason (by running fdisk /MBR from DOS prompt), you will erase the GRUB and render all systems listed in the menu.lst unbootable.
To install GRUB in MBR, you will need to boot from external media (floppy, live Linux CD). Then, once you reach the GRUB prompt, execute the following commands:
Find the GRUB root device:
find /boot/grub/stage1
GRUB will search for all available Stages 1 and present them. If you have more than one operating system image present (e.g. SUSE, Kubuntu, Mandriva), you will have more than one stage1 available. Example – Let’s say the computer has the following operating systems installed on different partitions:
- SUSE on (hd0,1)
- Kubuntu on (hd0,2)
- Mandriva on (hd0,4)
All these will be returned as potential roots for GRUB device (as each OS has its own files). If you wish to use SUSE GRUB, then you will setup the GRUB root device to (hd0,1):
root (hd0,1)
If you want Mandriva’s GRUB, then:
root (hd0,4)
If you know in advance what you want to do, you can skip the find command. Once you have decided on the root, you need to write the information to the MBR:
setup (hd0)
Finally, quit the GRUB prompt:
quit
As a sequence, the commands that you need are:
find /boot/grub/stage1 (optional)
root (hdX,Y)
setup (hd0)
quit
You can also setup GRUB on another drive or partition, but then you will have to chainloadGRUB to another bootloader for this to work. That’s it. Easy peasy orange squeasy!
Installing GRUB with grub-install
This method is considered less safe (according to the Manual), as it guesses the mapping. Still, for total newbs in need of dire help, this might be the preferred method. You only need to invoke a single command – namely, where to install the bootloader. Furthermore, this command can be written in several ways, all equivalent:
grub-install /dev/hda
grub-install /dev/hd0
grub-install ‘(hd0)’
grub-install hd0
After you have installed the GRUB, your operating systems should boot. Once booted, you can once again start playing with GRUB, manually changing settings – adding and removing entries, chainloading other bootloaders, or even hiding and unhiding partitions.
Setting up GRUB manually (after installation)
You can reconfigure or reinstall GRUB at any moment.
Backup!
First, before you make any changes to the GRUB configuration file, it is most warmly recommended that you backup the existing menu. You might even consider copying to another machine or printing the menu, in case things go bunkerous.
cp /boot/grub/menu.lst /boot/grub/menu.lst_backup
To access GRUB, execute the following command in Linux terminal:
sudo grub
After a few moments, the GRUB command line should show up. You can identify it by thegrub> prompt.

Alternatively, you can reach the GRUB command line during bootup. When the GRUB menu loads, press C on the keyboard.
Adding a new operating system to the GRUB menu
Let’s say you have installed yet another operating system on your machine, Sabayon. During the installation, you skip the GRUB setup. This means that the original GRUB remains untouched – and it does not contain an entry about Sabayon. For all practical purposes, Sabayon is not bootable.
Note: GRUB menu entries are called stanzas (probably a twist of instance?). So, we need to add Sabayon to the list. If you know where Sabayon is installed, you just need to add its entry to the menu.lst.
title Sabayon
root (hdX,Y)
chainloader +1
That’s it. You can also do this while booting the computer, without editing the menu. When the original GRUB comes up, press C to reach the command line. And then:
root (hdX,Y)
chainloader +1
Optionally, you will use the find command to get around. Basically, this is the whole of GRUB magic. As you can see, it’s very very simple. But for people who have never heard of GRUB and see long lists of strange commands, the prospect can be daunting. Now that we have covered the basics of grubbing, it’s time for extras and some more common problems.
Common problems
GRUB got deleted; how to restore?
This will often happen if you install Windows after Linux. Windows assumes it’s the only operating system in the world and does not try to live with existing information present in the MBR; it overwrites it. For people with dual-boot and very little knowledge of Linux, this is a disaster. Luckily, it’s very easily recoverable one.
The easy way
Use Super Grub Disk. I have written about this tool in detail in my article A (cool) list of Linux tools, under Rescue.
The hard way
- Boot from floppy disk or CD (any Linux live CD should do).
- Get to the grub command line.
find /boot/grub/stage1 (optional)
root (hdX,Y)
setup (hd0)
quit
The same as before!
Windows is installed on a non-first hard disk (Swapping)
GRUB cannot directly boot Microsoft operating systems. And sometimes, even chainloading may not work, especially if Windows is not installed on the first hard disk. Once again, you should remember that you should always install Windows first, on the first hard disk, on the first partition (the rule of three first). Nevertheless, even if you have Windows installed on a separate disk, you can solve the problem by swapping. You need to perform a virtual swapbetween hard disks. Like this:
map (hd0) (hd1)
map (hd1) (hd0)
After you add these two lines, you should be able to boot into Windows (or DOS, for that matter).
There is more than one Windows operating system installed on one hard disk (Hide/Unhide)
Again, Windows can cause problems if there’s more than one instance present on a hard disk, especially if installed on primary partitions. When you use the chainloader command, the control is transferred to the Windows boot loader, but which one?
The problem is easily solved by hiding and unhiding partitions. If GRUB hides a partition, it will not be visible by Windows and prevent a possible confusion. Vice versa, if you unhide a partition, Windows will detect it and be able to boot from it, without getting confused.
Here’s the example taken from the Manual that demonstrates this point. Let’s say we have Windows installed on the first and the second partition of your hard disk. We wish to boot thefirst instance of Windows. Then, we need to execute the following set of commands to make it all work:
unhide (hd0,0)
hide (hd0,1)
rootnoverify (hd0,0)
chainloader +1
makeactive
You resized a partition; GRUB is gone
This is an interesting case. It can happen after you use a partitioning or an imaging software to make changes to the Partition Table. Usually, this will happen when you make such a change in Windows. Linux will not be informed of the change, because Windows is blind to anything else on the machine save Microsoft thingies. Consequently, GRUB will suffer.
The solution is that most likely the filesystem is damaged and needs to be repaired. Boot from a live CD and execute the following commands, assuming you know where Linux partitions are. Check the filesystem:
fsck.ext2 /dev/hdXY
Replace X and Y with hard disk letter and partition number that you want to check (hda2, hdb3, etc.). Create the ext2/3 filesystem parameters again.
tune2fs -j /dev/hdXY
Now mount the root filesystem on /mnt/sysimage and run grub:
mount -t ext2 /dev/hdXY /mnt/sysimage
OR
mount -t ext2 /dev/hdXY /mnt/sysimage
cd /mnt/sysimage/sbin
grub