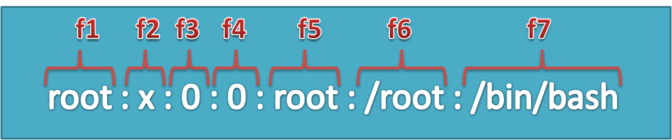
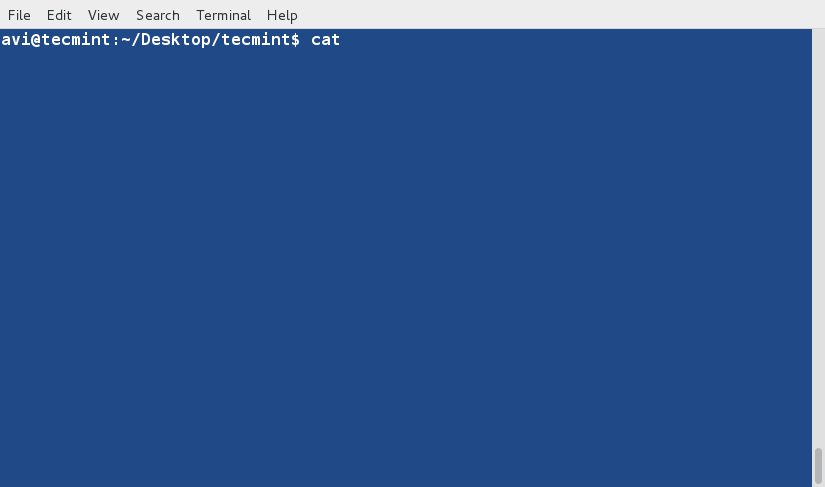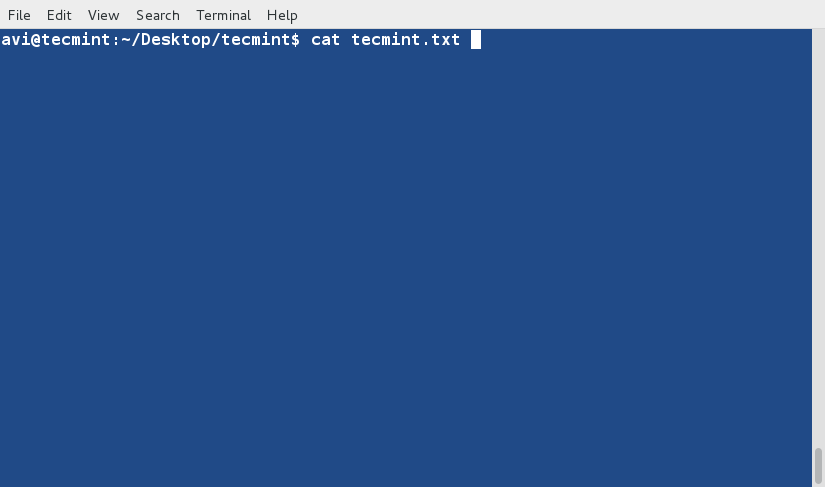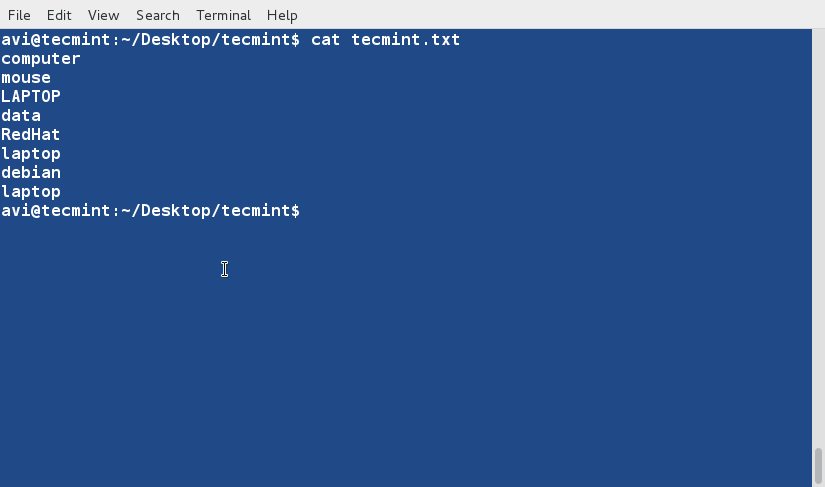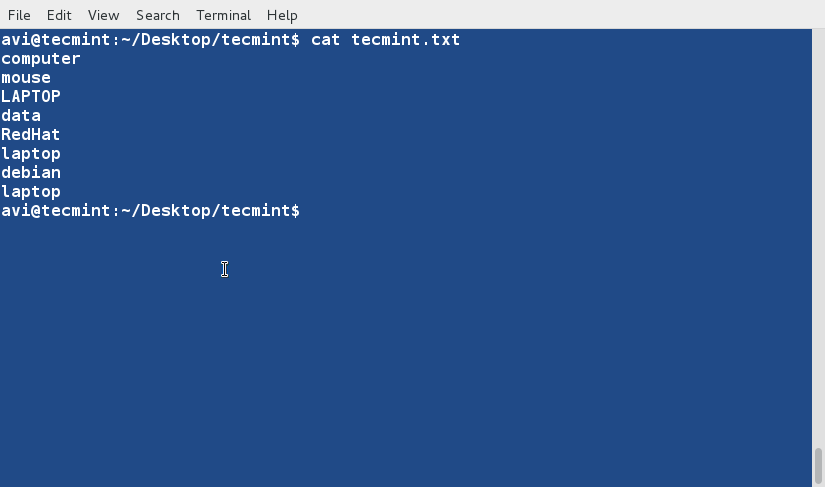
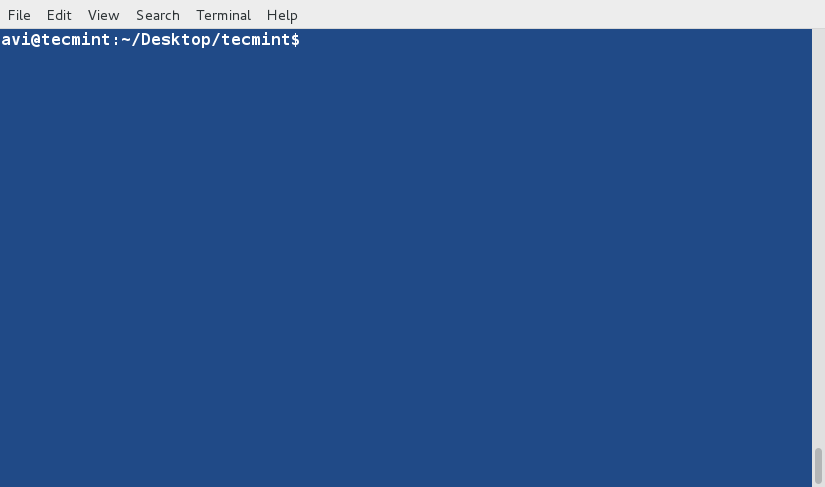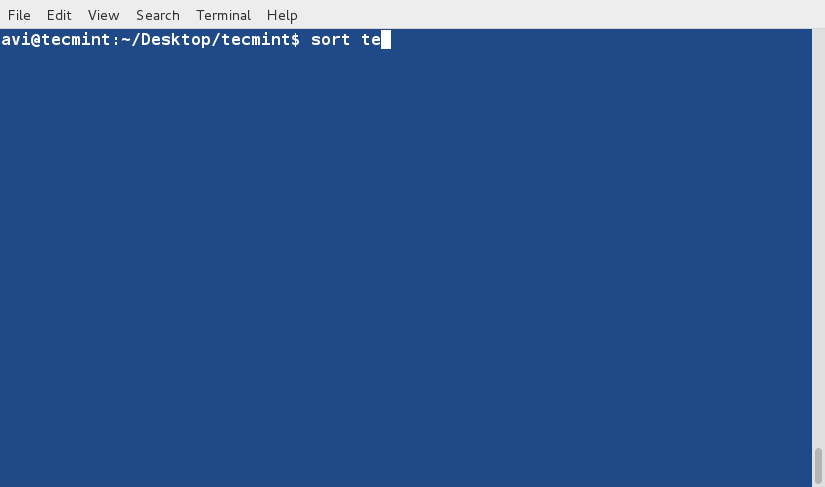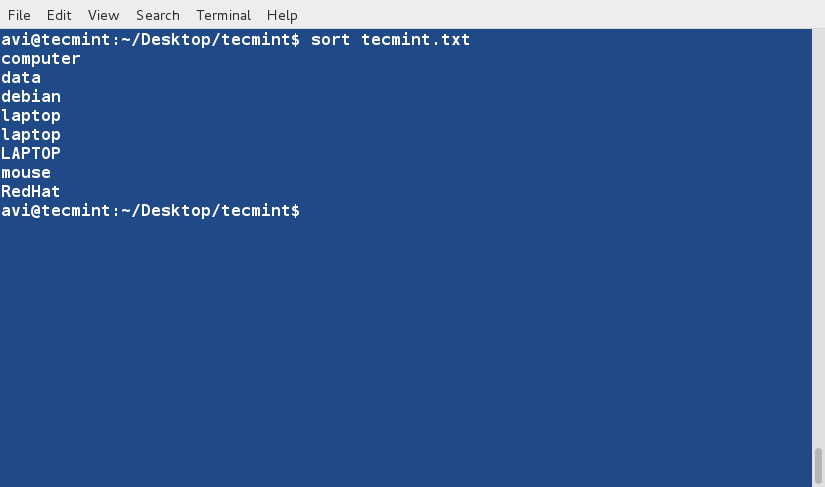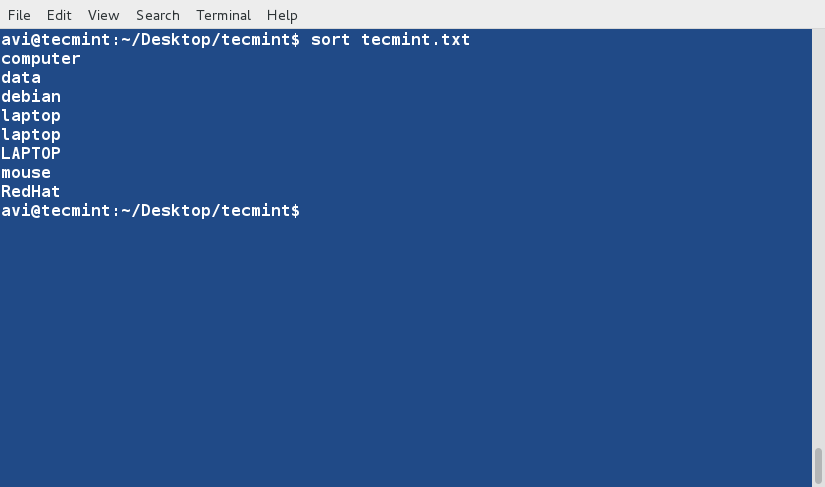
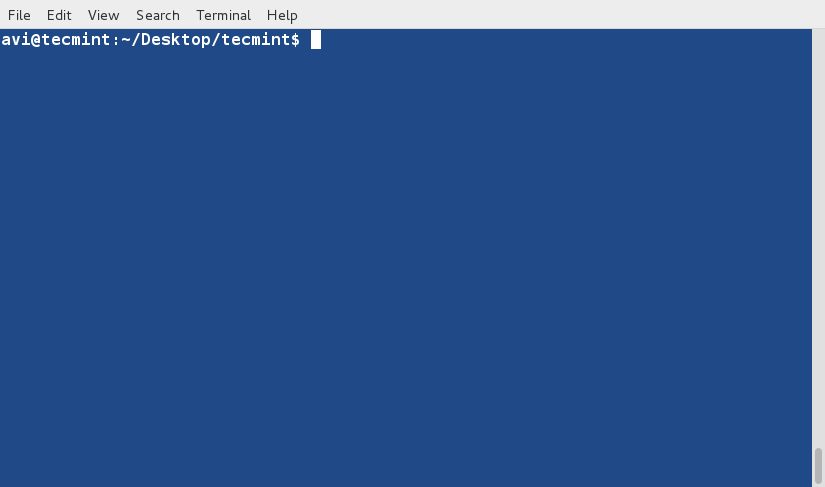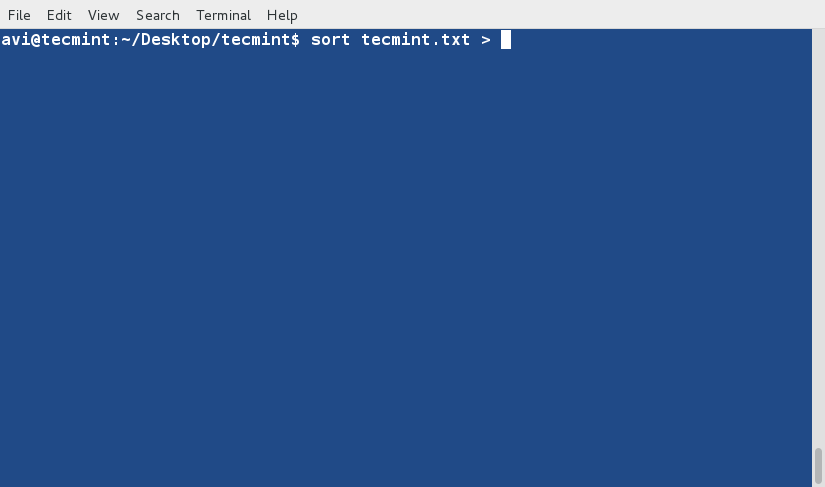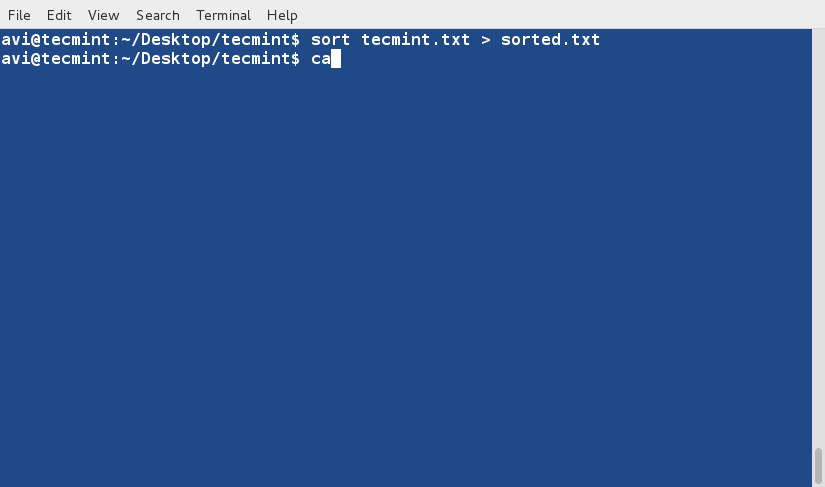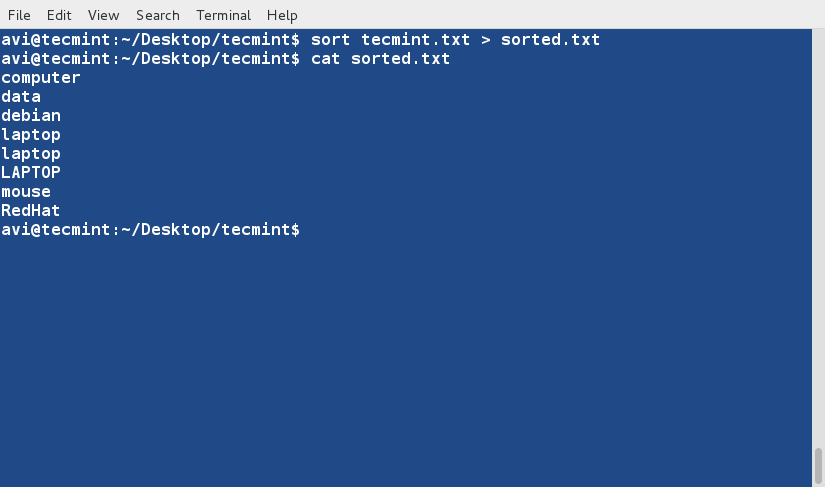
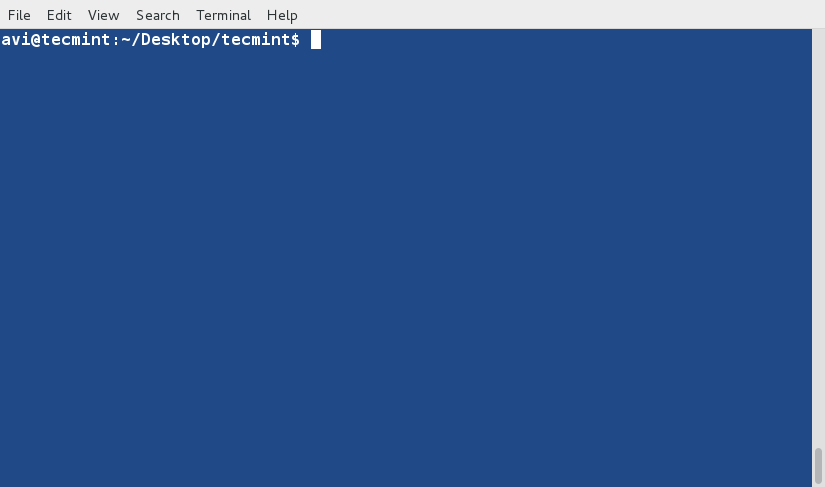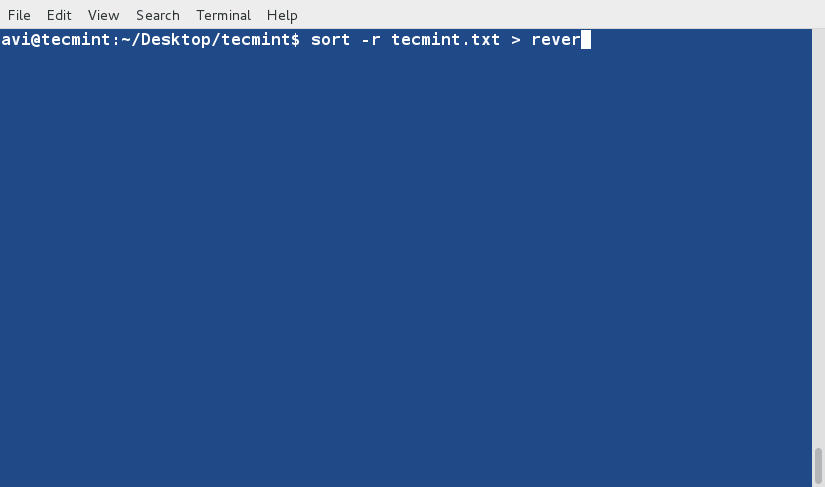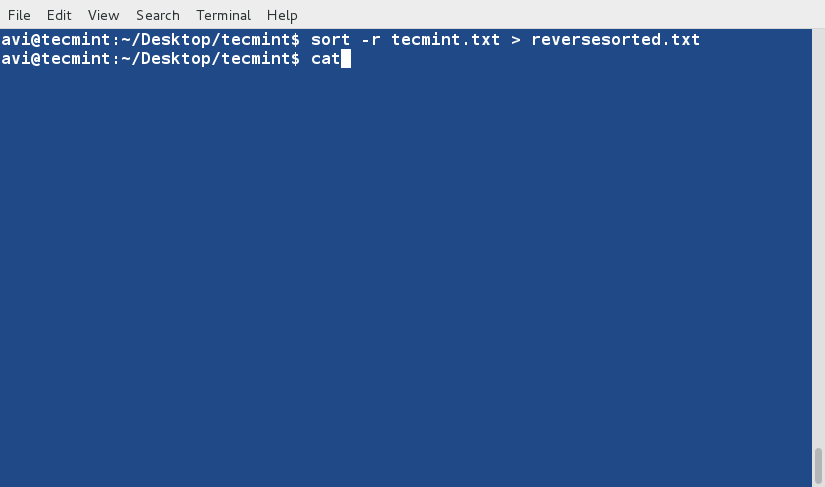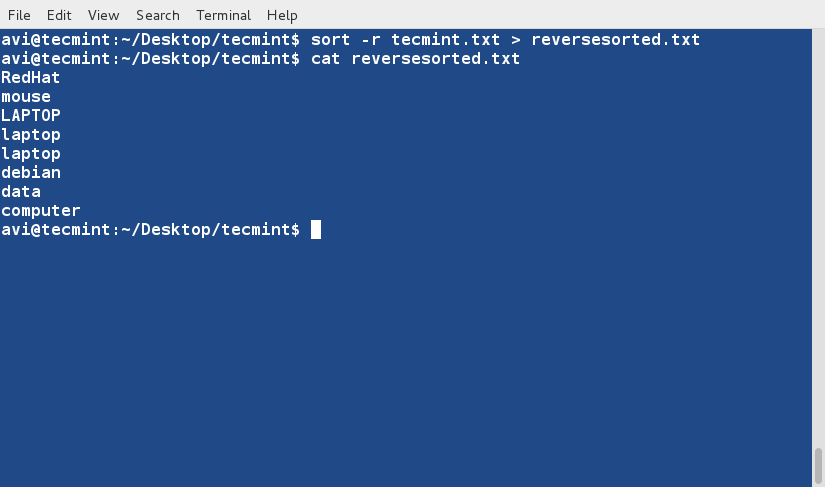
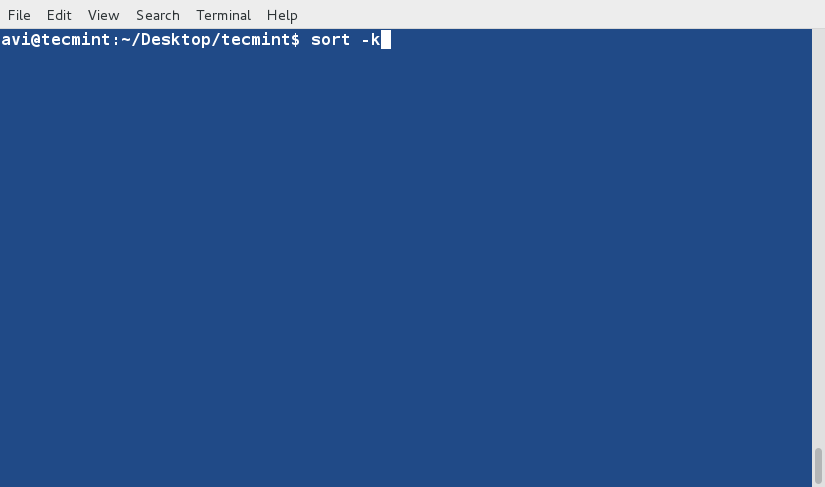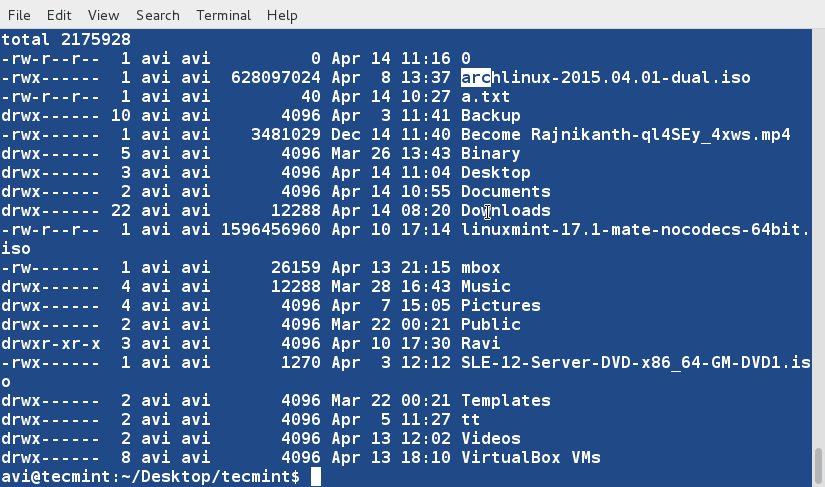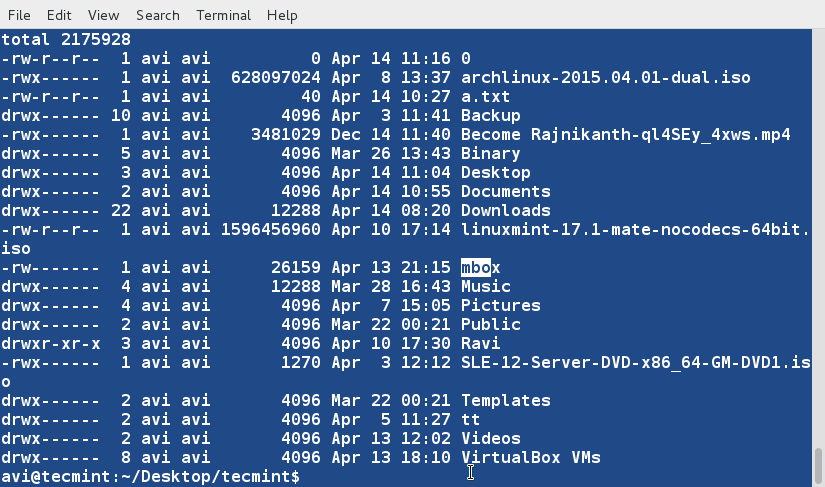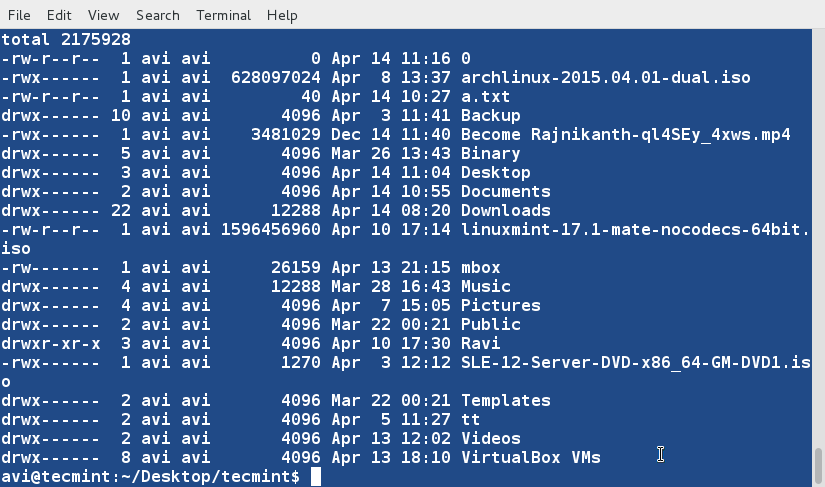
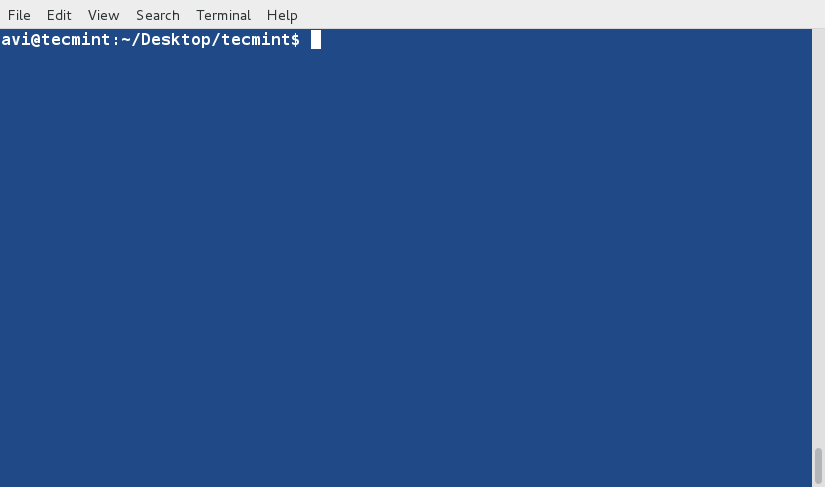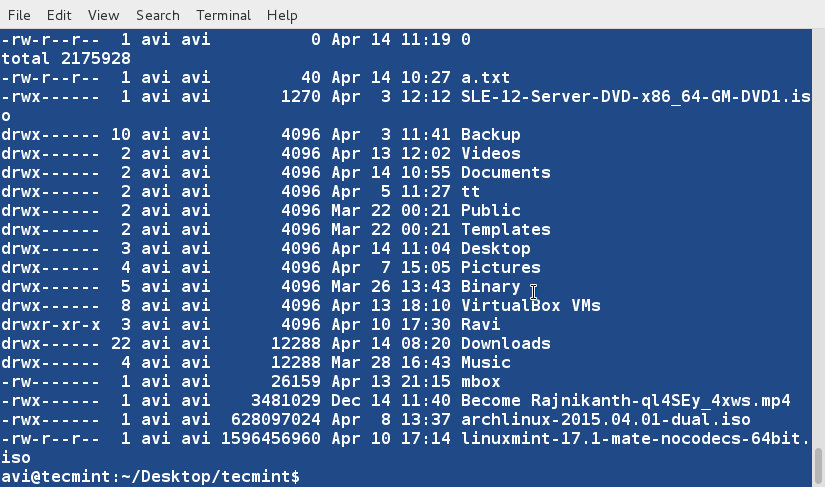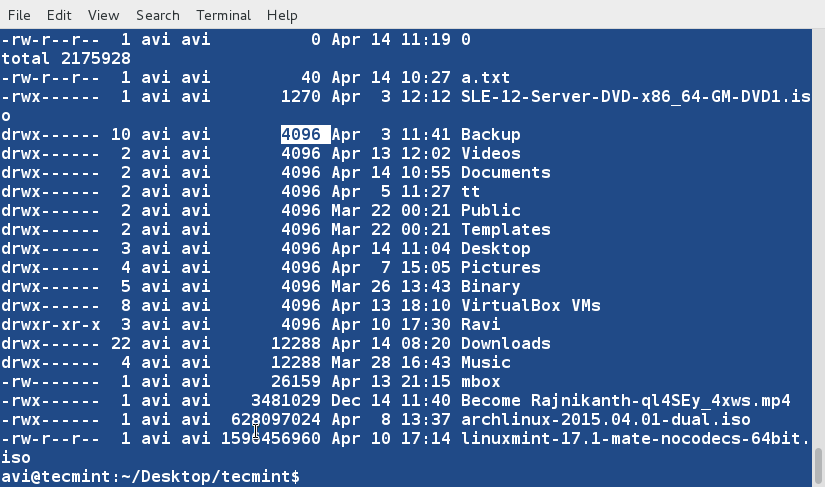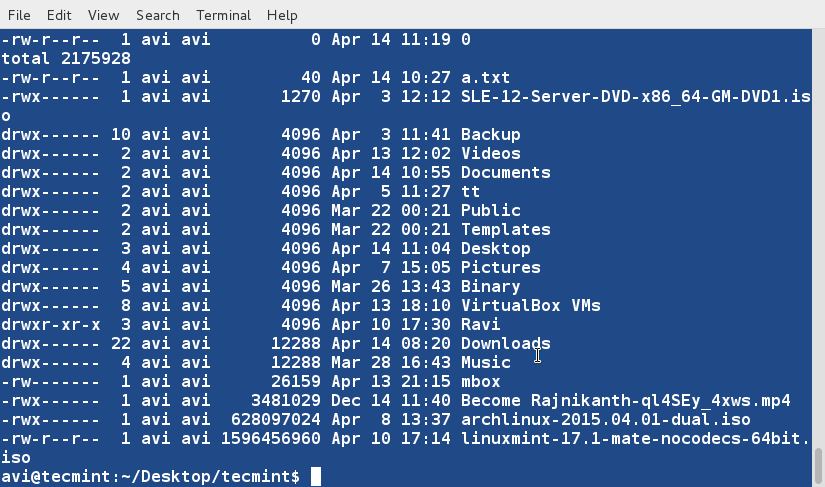
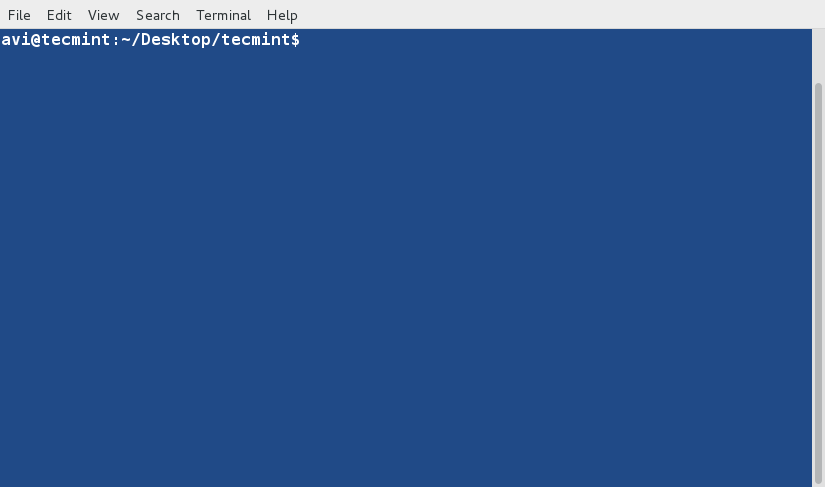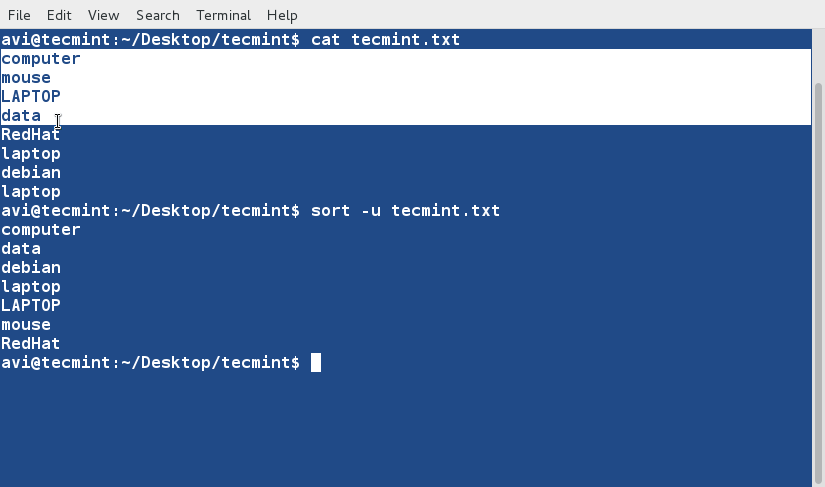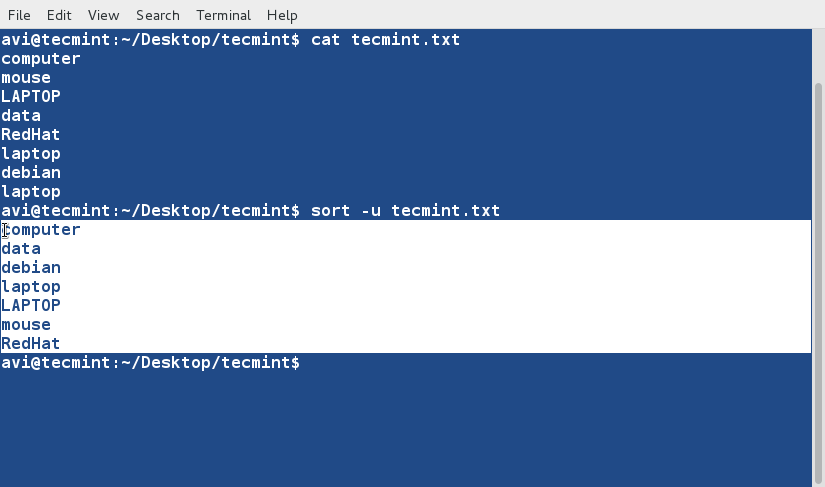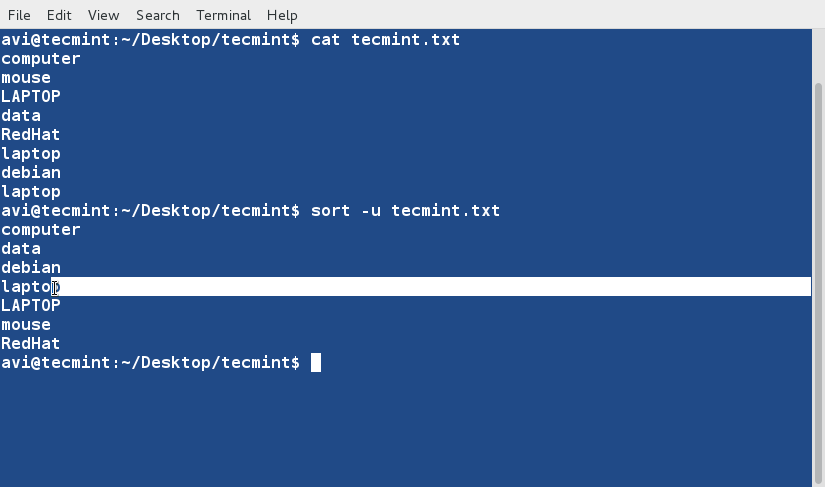
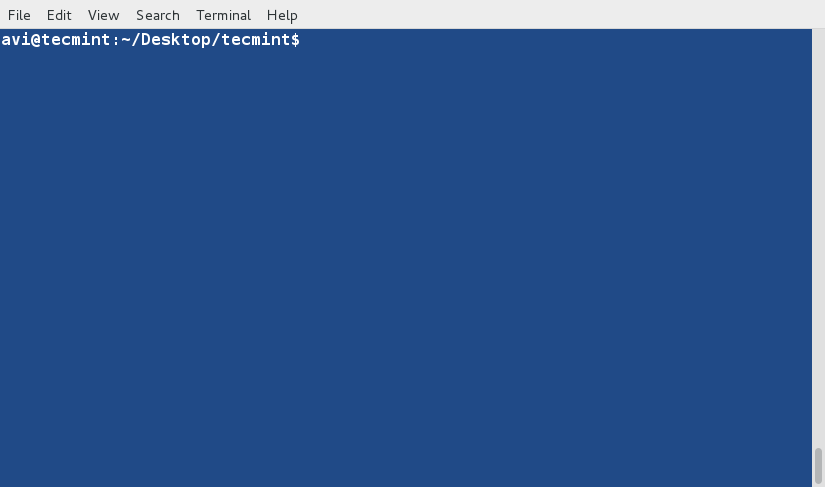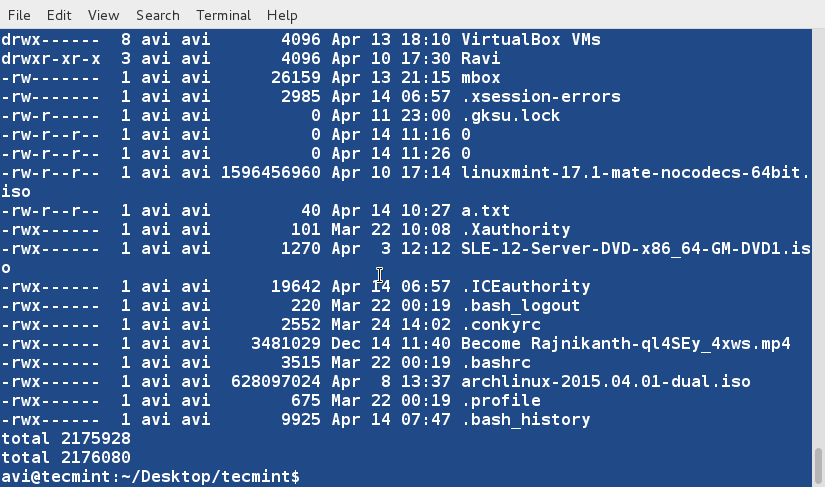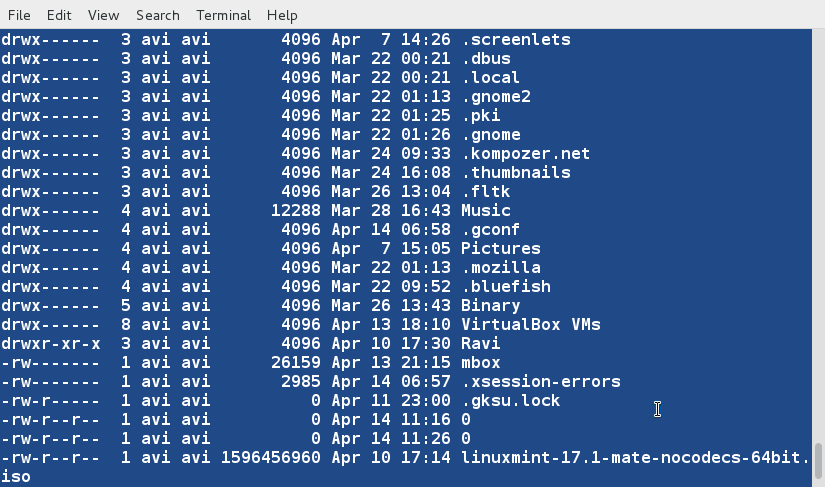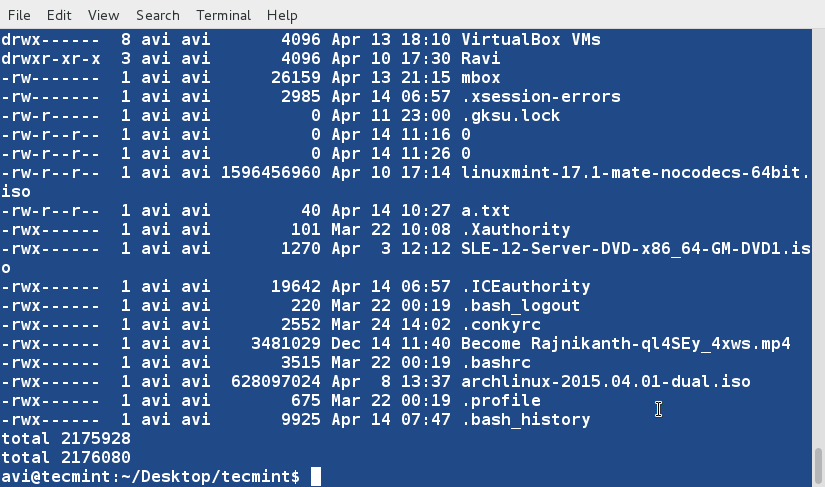
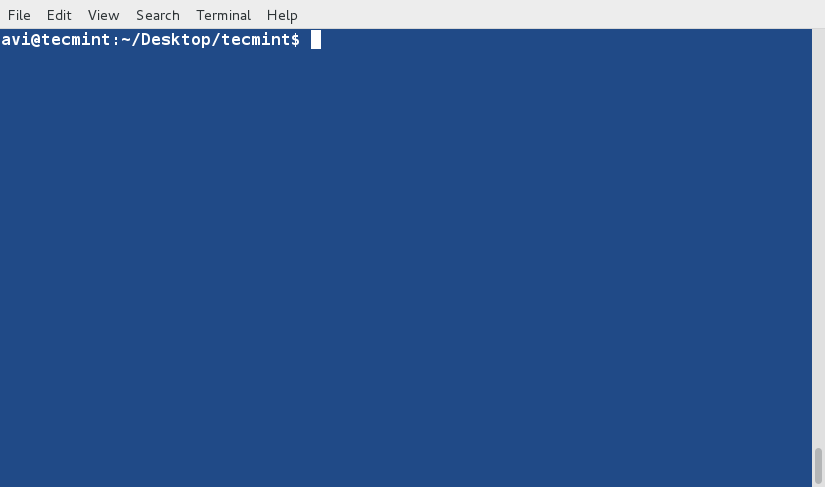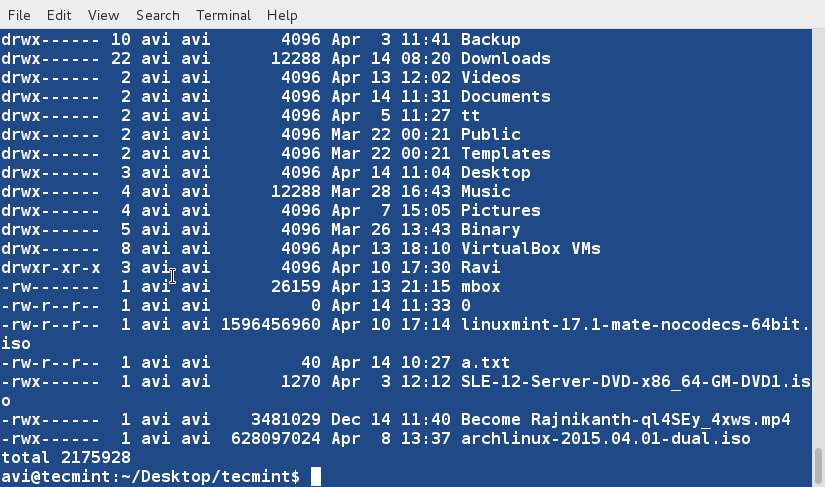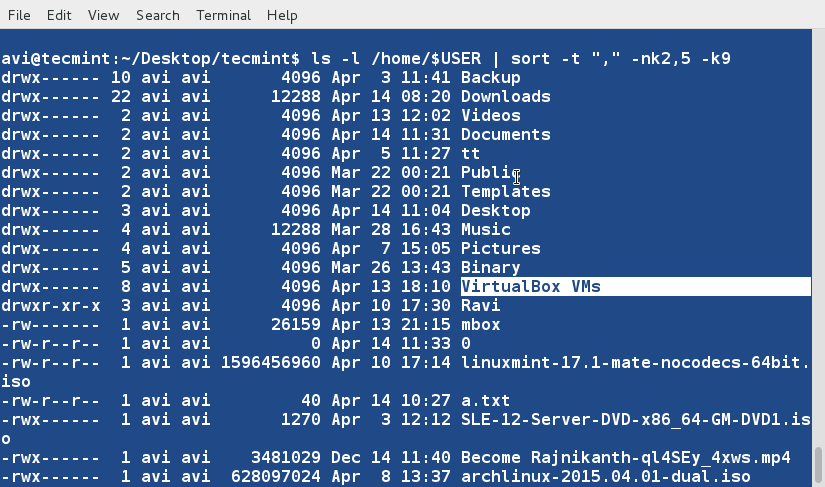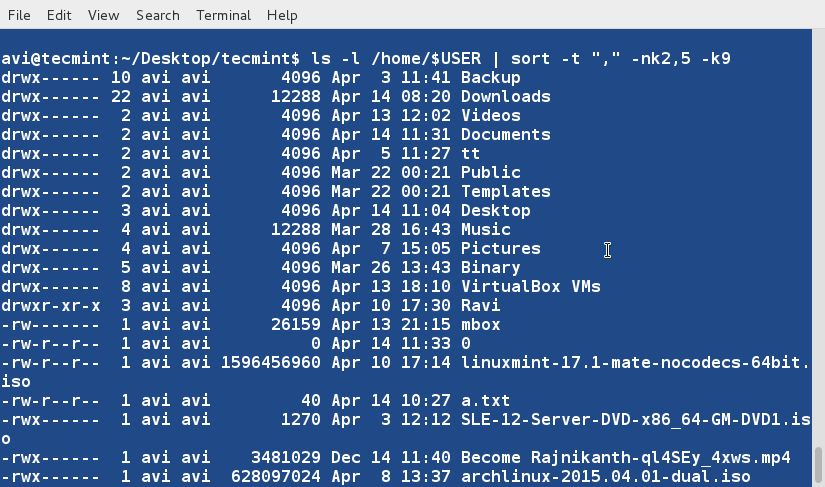
There are three basic types of Linux user accounts: administrative (root), regular, and service.
The Linux administrative root account is automatically created when you install Linux, and it has administrative privileges for all services on Linux Operating System. The root account is also known as super user
Regular users have the necessary privileges to perform standard tasks on a Linux computer such as running word processors, databases, and Web browsers. They can store files in their own home directories. Since regular users do not normally have administrative privileges, they cannot accidentally delete critical operating system configuration files.
Services such as Apache, Squid, mail, games, and printing have their own individual service accounts. These accounts exist to allow each of these services to interact with your computer.
Each user on a Red Hat Enterprise Linux system is assigned a unique user identification number, also known as a UID. UIDs below 500 are reserved for system users such as the root user and service users.
A user group is a group of one or more users. A user can be a member of more than one group. In Red Hat Enterprise Linux, when a user is added, a private user group (primary group) is created—meaning that a user group of the same name is created and that the new user is the sole user in that group.
There are 3 types of user accounts in linux.They are:
1> System Users
2> Root User(Administrator)
3> Other Users(Normal User)
In linux, Uid from 1 to 500 has been reserved for system
users,these are the default users of linux,so if anyone try
to assign Uid 500 to normal user then it wil give the error.
Linux User Types
There are different types of accessibility options provided by Linux, from which one can choose respective access as per requirement. Linux provides 5 different alternatives to choose the accessibility.
They are as listed below.
- Super User or Root User : A special kind of user account which holds all kind’s of permissions to do any alteration to a programs or services of Linux. Especially this kind of user account is used for system administration. He can control and limit the access of other User’s. As all the powers is vested for Root User, care has to be taken before performing each and every modifications, if anything goes wrong, no option left other than crash of Kernel. It is so sensitive with unlimited accessibility. 🙂 . Take care while logged in as Root 🙂
- System User: It is created by default by the OS. This type of user is similar to normal user but got more privileges and access to secure programs which normal user doesn’t got authentication.
- Normal User : These are the users which have been created by the Root and has limited access to the resources and need permission from Root to access any secure resources and services.
- Network User : Users opt this type of user account to check network activity and to manage them. Especially system administrator‘s and network engineer‘s uses this account for various network activities and to connect to different systems on the network using various services like LDAP, NFS, SAMBA,APACHE, NTP etc. {We will discuss about this services on the par in coming future}.
- Pseudo User: It’s a replica of Root User, is used when a user needs the permissions similar to Root User. Only Root User can give the access to thisuser account for others.
Every Users got their own identity and authenticity. When i say Identity of the User,UID (User identifier) comes into picture. UID is a unique identity, simply a number given to the user.
Every kind of User type as discussed above are given a particular range of UID’s.
Root User got the UID ‘0‘ . {As root user is prime and supreme authoritative, so he got the UID ” 0 “, This can be altered in the configuration file, which we come across later}
UID for System User lies with in the range of 1 to 499. {Don’t come to a conclusion that Linux OS can only provide 500 System Users. It’s just a default range provided by the OS, it can be altered and can add system users greater than 500 but less than a saturation value which depends on a type Linux OS}
UID for Normal User lies with in the range of > 500 <6000.
UID for Network User lies with in the range of >6000.
If you want to verify yourself or wanna see who you logged in as …
just simply do the following.
[root@localhost~]# whoami
root
Feed the above command to the terminal, that’s it. The output clears your ambiguity of as whom you are logged in. Ha ha.
![]()
Or else you can also try the below possibilities too . 🙂
[root@localhost~]#id
uid=0( root ) gid=0( root ) groups=0( root )
[root@localhost~]#
![]()
Hmm that’s cool. let’s give a try to below command too.
[root@localhost~]#id root
uid=0( root ) gid=0( root ) groups=0( root ), 1( bin ), 2 ( daemon ), 3 (sys ), 4 ( adm ), 6 ( disk ), 10 ( wheel )
[root@localhost~]#
![]()
The above commands are only to show and give an idea about the UID of root user, Don’t try to analyse the other stuff of output, they simply confuse you. So as of now you are in no hurry to know about them, in latter stages you can understand them in deeper and succinctly.
If you want to switch from one user account to other user account, we use a command called ” su “.
Syntax: su username
Ex:
[root@localhost~] # su charan
Password: ********* { Enter the password of charan}
[charan@localhost~]$
We can find the type of user as logged in easily by observing above commands. Root User is accompanied by the symbol ‘ # ‘, where as normal user is accompanied with ‘ $‘. It’s simple rite.
How To Use ‘Sudo’ And ‘Su’ Commands In Linux : An Introduction
Today We’re going to discuss sudo and su, the very important and mostly used commands in Linux. It is very important for a Linux user to understand these two to increase security and prevent unexpected things that a user may have to go through. Firstly we will see what these commands do then we’ll know the difference between both of them. So let’s get started.
Introduction to Linux command ‘sudo’
Introduction to Linux command ‘sudo’In Ubuntu Linux there is not root account configured by default. If users want root account password then they can manually set it up oo can use ‘sudo’. As we all know, Linux in many ways protects users’ computer being used for bad purposes by some nasty people around us. Using sudo is one of those good ways. Whenever a user tries to install, remove and change any piece of software, the user has to have the root privileges to perform such tasks. sudo, linux command is used to give such permissions to any particular command that a user wants to execute. sudo requires the user to enter user password to give system based permissions. For example user wants to update the operating system by passing command –
apt-get update
The above command will give following error-

apt-get update error
This error is due to not having root privileges to the user ‘sandy’. The root privileges can be required by passing sudo at the very beginning, like below-
sudo apt-get update
The above command will execute command and the operating system will update-

sudo apt-get update
As you can see when I used apt-get update that is a packaging management tool and through that I tried to update my system but it failed because to make this command work for me, I must have root privileges. So the next time I used the same command along with ‘sudo’ and this time sudo command asked user password to have root privileges to update system. After entering user password it system updated.But there may not be all the user accounts able to use sudo. As a system administrator, he has to give the rights whether any particular user can sudoer to do particulars admin tasks. To read that in description jump over here on the official page.
Some more examples of ‘sudo’ – sudo apt-get install {package-name}
 This command will install packages with the root privileges. This command will install packages with the root privileges.sudo apt-get remove {package-name}
This command will remove packages with the root privileges.sudo apt-get update {package-name}
This command will update packages with the root privileges.Introduction to Linux command ‘su’
The Linux command ‘su’ is used to switch from one account to another. User will be prompted for the password of the user switching to.
Users can also use it to switch to root account. If user types only ‘su’ without any option then It will be considered as root and user will be prompted to enter root user password.

su to switch to root account
As you can see su asked me root password and gave error ‘Authentication failure’ because I have not setup root password. I mentioned above in most distributions root password is not configured by default. Once the root password is setup then you can use it here to switch to root account very quickly.There is one more benefit of ‘su’ command that you can swith to any of the user account without user password. No need to remember different passwords for different user account; just user ‘su’.
How to switch to root user without configuring root password
Switching to root user without configuring root password seems to be confusing because above I said to switch to root user the normal user needs to configure root password manually. But stop! Here is a way to do that without configuring root password; just use ‘sudo’.We can use sudo and enter normal user password to switch to root user. Here see how we can do that with the power of sudo –

switching to root user with user password
Using ‘su’ command to have functionality similar to ‘sudo’If user only uses ‘su’ command and want to use ‘su’ as ‘sudo’ then it can be done. (here root password is assumed to have been configured because user is familiar with ‘su’.)To achieve same sudo functionality to execute any single command user has to use ‘-c’ option of ‘su’. Here is how to do it –
$ su -c apt-get install vlc
After hitting enter user will be prompted for password and obviously it’s for root password because we’re using ‘su’ command.
Using ‘sudo’ command to have functionality similar to ‘su’Above we have seen ‘su’ having similar functionality as sudo and it’s time to see how we can do same with the command ‘sudo’ and achieve same ‘su’ functionality.To achieve same ‘su’ functionality in ‘sudo’ just use ‘-i’ option of ‘sudo’. Here is how we can do it –

using ‘sudo’ same as ‘su’
When user hits enter, it will ask password its the user password not the root password.It’s all done!
$ man sudo
$ man su |
7 Linux sudo Command Tips and Tricks
Using sudo command, an user can execute root only commands.
In this article, let us review how to setup sudo environment along with some sudo command examples, tips, and tricks.
1. Set up sudo Environment in /etc/sudoers
You can provide sudo privilege to an individual user or a group by modifying /etc/sudoers.
sudo access to an user
To provide sudo access to an individual user, add the following line to the /etc/sudoers file.
sathiya ALL=(ALL) ALL
In the above example:
- sathiya : name of user to be allowed to use sudo
- ALL : Allow sudo access from any terminal ( any machine ).
- (ALL) : Allow sudo command to be executed as any user.
- ALL : Allow all commands to be executed.
sudo access to a group
To provide sudo access to a group, add the following line to the /etc/sudoers file.
%programmers ALL=(ALL) ALL
In the above example:
- programmers : name of group to be allowed to use sudo. Group name should be preceded with percentage symbol.
- ALL : Allow sudo access from any terminal ( any machine ).
- (ALL) : Allow sudo command to be executed as any user.
- ALL : Allow all commands to be executed.
Note: Ubuntu users are already familiar with sudo command, as you’ll use sudo apt-get install to install any package. On Ubuntu, sudo is already setup for your username as shown below. i.e All users who belong to admin group has access to execute root commands using sudo.
$ sudo cat /etc/sudoers %admin ALL=(ALL) ALL $ grep admin /etc/group admin:x:115:sathiya
2. Executing a command as super user
Once the sudo access is provided to your account in /etc/sudoers, you can pass any root command as an argument to the sudo command. For example, mount can only be done by root. But, a normal user can do mount as shown below using sudo.
$ sudo mount /dev/sda3 /mnt
Note: If you are executing sudo for the first time in a shell it will ask for the password ( current user password ) by default.
3. Forgot to Use Sudo in Vim? No Worries. Save file Trick in vim with sudo
When you have opened a file that can be saved only by root user using vim (without using the sudo command), you can do the following.
For example, if you want to edit the file /etc/group that can only be saved by root user, you typically do the following. When you do a :w, no problem, it will work, as it was opened using sudo command.
$ sudo vim /etc/group :w
What if you’ve forgot to give sudo when you’ve opened the /etc/group file as shown below? In this case, instead of coming out of the file (and loosing all your changes) and executing the vim command with sudo, you can do the following.
$ vim /etc/group :w !sudo tee %
Note: “:w !sudo tee %” will save the file as root privilege, even if you didn’t use sudo command to open it.
4. Forgot to give sudo for root command? Do it again using !!
If you’ve forgot to give sudo for a command that requires root privilege, instead of typing the command with sudo again, you can simply do sudo !! as shown below.
$ head -n 4 /etc/sudoers head: cannot open `/etc/sudoers' for reading: Permission denied $ sudo !! sudo head -n 4 /etc/sudoers # /etc/sudoers # # This file MUST be edited with the 'visudo' command as root. #
5. Get Root Shell Access using Sudo
To get a root shell from your user account, do the following.
$ sudo bash
Once you get the root shell, you can execute any root command without having to enter sudo in front of it every time.
6. Built in commands won’t work with Sudo – Command not found
sudo invokes an executable as the another user, so bash built in commands won’t work. It will give “sudo command not found” error as shown below.
For example, umask is a bash built-in command, which will not work when used along with sudo as shown below.
$ sudo umask sudo: umask: command not found
Work-around: To use bash shell built-in command in sudo, first get the root shell, by doing ‘sudo bash’ and then execute the shell built in command.
7. View Unauthorized Sudo command executions from auth.log
When an user who doesn’t have sudo permission, tries to execute sudo command, they’ll get following error message.
$ sudo ls / [sudo] password for test: raj is not in the sudoers file. This incident will be reported.
Anytime this happens, it will be logged in the /var/log/auth.log file for sysadmins to view any unauthorized sudo access.
Sep 25 18:41:35 sathiya sudo: raj : user NOT in sudoers ; TTY=pts/4 ; PWD=/home/raj ; USER=root ; COMMAND=/bin/ls /
Linux / Unix: id Command Examples
Iam a new Linux and Unix system user. How do I find out the user and groups names and numeric IDs of the current user or any users on my server? How can I display and effective IDs on the system using command line options? In Linux, how do I find a user’s UID or GID?
To find a user’s UID (user ID) or GID (group ID) and other information in Linux/Unix-like operating systems, use the id command.
This command is useful to find out the following information:
- Find a specific user’s UID
- Find a specific user’s UID
- Find out all the groups a user belongs to
- Find the UID and all groups associated with a user
- Display security context of the current user
Purpose
Displays the system identifications of a specified user.
id command syntax
The basic syntax is:
id
id [UserNameHere]
id [options]
id [options] [UserNameHere]
By default id command shows the the user and group names and numeric IDs, of the calling process i.e. the current user who runs the id command on screen. If a login name or user ID ([UserNameHere]) given on command line, the user and group IDs of that user are displayed.
id command examples
Let us see how to find a user’s UID or GID on Linux or Unix-like operating systems using 13 id command practical examples. First, open the Terminal application and then type:
Display your own UID and GID
Type the command:
id
Sample outputs:

How do I find a specific user’s UID?
In this example, find a vivek user’s UID, type:
id -u {UserNameHere}
id -u vivek
Sample outputs:
501
How do I find a specific user’s GID?
In this example, find a vivek user’s GID, run:
id -g {UserNameHere}
id -g vivek
Sample outputs:
20
How do I see the UID and all groups associated with a user name?
In this example, find the UID and all groups associated with a user called ‘root’, enter:
id {UserNameHere}
id root
Sample outputs:
uid=0(root) gid=0(wheel) groups=0(wheel),1(daemon),2(kmem),3(sys),4(tty),5(operator),8(procview),9(procmod),12(everyone),20(staff),29(certusers),61(localaccounts),80(admin),33(_appstore),98(_lpadmin),100(_lpoperator),204(_developer),398(com.apple.access_screensharing),399(com.apple.access_ssh)
Find out all the groups a user belongs to…
In this example, display the UID and all groups associated (secondary groups) with a user called ‘vivek’, run:
id -G {UserNameHere}
id -G vivek
Sample outputs
20 12 61 79 80 81 98 33 100 204 398 399
Display a name instead of a UID/GID
By default, id command displays number for the -G, -g and -u options. You can force id command to display the name of the UID or GID instead of the number for the -G, -g and -u options by passing the -n option as follows:
id -ng {UserNameHere}
id -nu {UserNameHere}
id -nG {UserNameHere}
id -nG vivek
Sample outputs:
staff everyone localaccounts _appserverusr admin _appserveradm _lpadmin _appstore _lpoperator _developer com.apple.access_screensharing com.apple.access_ssh
How do I display real ID instead of the effective ID for specified user?
You can show the real ID for the -g, -G and -u options instead of the effective ID by passing the -r option:
id -r -g {UserNameHere}
id -r -u {UserNameHere}
### [NOTE]###########################
### -r and -G only works on Linux ###
#####################################
id -r -G {UserNameHere}
id -r -u vivek
Sample outputs:
501
How do I display SELinux show security context on Linux?
To display only the security context of the current user, type:
### [NOTE]########################### ### This is a Linux only option ### ##################################### id -Z
Sample outputs:
unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023
Unix specific feature: Show process audit user ID
To display the process audit user ID and other process audit properties, which requires privilege. This option works on a few Unix-like operating systems such as FreeBSD or Unix:
### [NOTE]########################### ### This is a Unix only option ### ##################################### id -A
Output is displayed in the following format from my Apple OS X/FreeBSD:
auid=501 mask.success=0xffffffff mask.failure=0xffffffff termid.port=0x03000002 asid=100004
Shell variables related to UID and EID
Modern shell such as bash/ksh may set the following variables:
- EUID – Expands to the effective user ID of the current user, initialized at shell startup. This variable is readonly.
- UID – Expands to the user ID of the current user, initialized at shell startup. This variable is readonly.
You can print them using echo or printf shell commands as follows:
echo "Your UID : $UID" echo "Your EID : $EUID"
Sample outputs:
Your UID : 501 Your EID : 501
Your shell use id command to set EUID and UID in the system-wide startup file such as /etc/profile. Here is a snippet from Linux based system:
....
..
if [ -x /usr/bin/id ]; then
if [ -z "$EUID" ]; then
# ksh workaround
EUID=`id -u`
UID=`id -ru`
fi
USER="`id -un`"
LOGNAME=$USER
MAIL="/var/spool/mail/$USER"
fi
....
..
Determining root privileges in a script
Linux and Unix sysadmin relates shell scripts must be run by root user. The following shell script shows how to determining root privileges in a script:
#!/bin/bash
## if root user not running this script, die with a message on screen ##
if [ $(id -u -r) -ne 0 ]
then
echo "Requires root privileges. Please re-run using sudo."
exit 1
fi
## add sysadmin related command below ##
Or you can use EUID as described above in a shell script:
(( EUID )) && { echo 'Requires root privileges. Please re-run using sudo.'; exit 1; }
|| echo 'Running script as root...'
id command options
| Option | Purpose | OS |
| -g | Display only the effective group ID | ALL |
| -G | Display all group IDs | ALL |
| -u | Display only the effective user ID | ALL |
| -n | Display a name instead of a number, for -u or -g | ALL |
| -r | Display the real ID instead of the effective ID, with -u or -g | ALL |
| -Z | Show only the security context of the current user | SELinux |
| -A | Display the process audit user ID and other process audit properties | Selected Unix-like |
Linux / Unix: w Command Examples
Iam a new Linux and Unix system user. How do I list current users and find out what they’re doing on Linux or Unix-like operating system using shell prompt?
The w command displays a list of all logged in to the server and what they are doing. This command is similar to who command, but ends up displaying more information about logged in users.
Purpose
Display who is logged into the Linux/Unix server and what they are doing at command execution time.
Syntax
The basic syntax is as follows:
w
w [UserNameHere]
w [UserNameHere1] [UserNameHere2]
w [options]
w [options] [UserNameHere]
Understanding w command output / header
The w command shows the following information about each user and their process on the system:
- USER – User name.
- TTY – Terminal type such as pts/0 or console.
- FROM – The remote host name or IP address.
- LOGIN@ – Login time.
- IDLE – Idel time.
- JCPU – The JCPU time is the time used by all processes attached to the tty.
- PCPU – The PCPU time is the time used by the current process displayed in WHAT field.
- WHAT – The command line of USER’s current process.
w command examples
To see who is currently logged in and what they are doing on your Linux/Unix-based server, type:
$ w
Sample outputs:

The first line of output in this example, displays the current time of day, how long the system has been running, the number of users logged into the system, and the load averages.
Hide the header
To suppress the heading pass the -h option:
$ w
Sample outputs:
vivek pts/0 192.168.1.6 14:10 3:24m 2.15s 0.00s dbus-launch --auto root pts/1 192.168.1.6 14:51 1:41m 0.16s 0.00s pager -s nixcraft pts/2 192.168.1.6 14:52 13:07 0.41s 0.02s vi /etc/passwd root pts/3 192.168.1.6 17:21 3.00s 0.12s 0.01s w -h
Ignore usernames
$ w -u
Use short output format
To hide the login time, JCPU or PCPU times:
$ w -s
Sample outputs:
17:42:36 up 3:36, 4 users, load average: 0.00, 0.01, 0.05 USER TTY FROM IDLE WHAT vivek pts/0 192.168.1.6 3:31m dbus-launch --autolaunch 9ee90112ba2cb root pts/1 192.168.1.6 1:48m pager -s nixcraft pts/2 192.168.1.6 20:12 vi /etc/passwd root pts/3 192.168.1.6 4.00s w -s
Hide/show the FROM field
Toggle printing the from (remote hostname) field. The default as released is for the from field to not be printed:
$ w -f
How do I show information about the specified user only?
To see information about user named ‘vivek’, type:
$ w vivek
Sample outputs:
17:40:02 up 3:34, 4 users, load average: 0.00, 0.01, 0.05 USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT vivek pts/0 192.168.1.6 14:10 3:29m 2.15s 0.00s dbus-launch --auto
w command options
| Option | Description |
| -h | Do not print header |
| -u | Ignore current process username |
| -s | Short format |
| -f | Show remote hostname field |
| -o | Old style output |
| --help | Display this help and exit |
| -V | Output version information and exit |
Linux / Unix: who Command Examples To List Users on The Systems
Iam a new Linux and Unix system user. How do I display who is logged on my Linux or Unix-like operating system using shell prompt?
You need to use who command to display users who are currently logged in your server.
This command is useful to find out the following information:
- Time of last system boot.
- Current run level.
- List of logged in users and more.
Purpose
Display who is on the system.
Syntax
The basic syntax is as follows:
who
who am i
who [options] [File]
who --help
who --version
who | grep 'userNameHere'
Where,
- If no non-options provided, who displays the following information for each user currently logged on:
- login name
- terminal line
- login time
- remote hostname or X display
- If you give one non-option argument, who uses that instead of a default system-maintained file such s /var/run/utmp as the name of the file containing the record of users logged on.
- If given two non-option arguments, who prints only the entry for the user running it preceded by the hostname. Traditionally, the two arguments given are ‘am i’, as in ‘who am i’.
who command examples
To show a list of all the users currently logged in to the system, type:
$ who
Sample outputs:

The sample output in this example shows that the user vivek is logged in on pts/0, and has been on since 14:10 on 27 January. To display line of column headings pass the -H option:
$ who -H
To show only hostname and user associated with stdin (usually keyboard), enter:
$ who -m
To show active processes spawned by init:
$ who -p
To show user’s message status as +, – or ?, enter:
$ who -T
Show or list users logged in
Type the command:
$ who -u
Show time of last system boot
To display time of last system boot pass the -b option to who command:
$ who -b
Sample outputs:
system boot 2014-01-05 10:02
The output in this example, shows that the system was booted since 10:02 on 05 January.
Show dead processes on the system
You need pass the -d option to who command:
$ who -d
OR
$ who -d -H
Sample outputs:
NAME LINE TIME IDLE PID COMMENT EXIT
pts/1 2014-01-11 09:17 56094 id=ts/1 term=0 exit=0
pts/2 2014-01-05 15:46 11070 id=ts/2 term=0 exit=0
pts/2 2014-01-08 03:31 3614 id=/2 term=0 exit=0
pts/1 2014-01-11 16:54 64559 id=/1 term=0 exit=0
pts/3 2014-01-11 17:13 15818 id=/3 term=0 exit=0
pts/4 2014-01-25 11:02 46807 id=ts/4 term=0 exit=0
Show system login processes
To just display system login processes pass the -l option:
$ who -l
OR
$ who -l -H
Sample outputs:
NAME LINE TIME IDLE PID COMMENT LOGIN tty2 2014-01-05 10:03 8750 id=2 LOGIN tty1 2014-01-05 10:03 8748 id=1 LOGIN tty3 2014-01-05 10:03 8752 id=3 LOGIN /dev/ttyS1 2014-01-05 10:03 8747 id=v/tt LOGIN tty4 2014-01-05 10:03 8754 id=4 LOGIN tty5 2014-01-05 10:03 8756 id=5 LOGIN tty6 2014-01-05 10:03 8758 id=6
Count all login names and number of users logged on the system
To count all login names and number of users logged on:
$ who -q
Sample outputs:

Display the current runlevel
To display the current system runlevel, type:
$ who -r
Sample outputs:
run-level 3 2014-01-05 10:02
You can combine -r and -b options as follows:
$ who -r -b
Sample outputs:
system boot 2014-01-05 10:02
run-level 3 2014-01-05 10:02
Display all
The -a is same as same as -bdprtTu options as discussed earlier:
Sample outputs:
NAME LINE TIME IDLE PID COMMENT EXIT
system boot 2014-01-05 10:02
run-level 3 2014-01-05 10:02
LOGIN tty2 2014-01-05 10:03 8750 id=2
LOGIN tty1 2014-01-05 10:03 8748 id=1
LOGIN tty3 2014-01-05 10:03 8752 id=3
LOGIN /dev/ttyS1 2014-01-05 10:03 8747 id=v/tt
LOGIN tty4 2014-01-05 10:03 8754 id=4
LOGIN tty5 2014-01-05 10:03 8756 id=5
LOGIN tty6 2014-01-05 10:03 8758 id=6
root + pts/0 2014-01-27 03:37 . 11149 (10.1.6.120)
pts/1 2014-01-11 09:17 56094 id=ts/1 term=0 exit=0
pts/2 2014-01-05 15:46 11070 id=ts/2 term=0 exit=0
pts/2 2014-01-08 03:31 3614 id=/2 term=0 exit=0
pts/1 2014-01-11 16:54 64559 id=/1 term=0 exit=0
pts/3 2014-01-11 17:13 15818 id=/3 term=0 exit=0
pts/4 2014-01-25 11:02 46807 id=ts/4 term=0 exit=0
who command options
| Option | Description |
| -a | Same as -b -d –login -p -r -t -T -u |
| -b | Time of last system boot |
| -d | Print dead processes |
| -H | Print line of column headings |
| -l | Print system login processes |
| -m | Only hostname and user associated with stdin |
| -p | Print active processes spawned by init |
| -q | All login names and number of users logged on |
| -r | Print current runlevel |
| -t | Print last system clock change |
| -T | Add user’s message status as +, – or ? |
| -u | List users logged in |